



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
录井资料处理与模式识别技术在长庆油田录井解释评价中的应用
[刘涛①  , 乔德民
, 乔德民② , 晏巍③ , 刘永炜③ , 方铁园① , 王海涛① ]
, 乔德民|
|


作者简介:刘涛 助理工程师,1970年生,2009年毕业于吉林师范大学电子信息工程技术专业,现从事石油勘探钻井现场录井管理工作。通信地址:124000辽宁省盘锦市兴隆台区高新技术产业园盘锦中录。电话:(0427)3231180。E-mail: hcrlt@163.com
为了提高录井资料的应用价值,尝试利用录井智能解释软件对多项录井资料进行标准化、数字化处理,然后进行敏感参数提取,并利用模式识别技术充分挖掘新解释方法。基于该思路,阐述了多种资料处理技术,包括保留时间校正技术、指纹对别技术、谱图重构技术、敏感参数提取技术,并详细介绍了实现过程。利用多种模式识别技术所建立的新解释方法,包括相似度分析、多元统计分析等,在长庆油田后期生产中均取得了较好的应用效果,对录井技术创新发展有一定的借鉴意义。
To improve the application value of mud logging data, this paper tries to use mud logging intelligent interpretation software to standardize and digitize multiple mud logging data, then extracts sensitive parameters, and uses pattern recognition technology to fully mine new interpretation methods. Based on this idea, multiple data processing techniques consisted of retention time correction, fingerprint contrast and discrimination, spectrogram reconstruction and sensitive parameter extraction are expounded, and the implementation process is introduced in detail. The multiple pattern recognition technologies are used to establish similarity analysis, multivariate statistical analysis and other new interpretation methods. In Changqing Oilfield, good application effect has been achieved in later stage of production, which has certain reference significance for the innovation and development of mud logging technology.
近年来, 由于设备不同、进样方式不同等原因常出现录井资料采集不规范[1], 甚至资料乱、差等问题[1, 2], 而且录井资料解释评价多数还基于以人为中心的处理体系, 分析结果干扰因素大, 部分录井资料的实用价值并没有得到充分挖掘与体现, 制约了录井技术的快速发展[3]; “ 十四五” 以来, 国家高度重视发展工业互联网[4], 录井技术创新研究新方法应顺应时代发展。盘锦中录油气技术服务有限公司研发了录井智能解释软件, 以数据作为基础资料分析研究, 打破单一利用常规二维图板法、经验法等传统的解释做法, 尝试利用配套的智能解释软件, 对轻烃、热蒸发烃气相色谱录井技术采集谱图开展保留时间校正[5]、指纹对别技术的标准化资料处理[6], 利用谱图重构技术对核磁共振录井谱图进行二次处理, 并由计算机对多项录井资料进行敏感参数提取, 在智能解释软件模型管理单元中生成了相似度分析、多元统计分析等可视化图板, 其规律性明显, 在后期生产应用中解释符合率显著提高, 具有较好的推广应用价值。
本文以轻烃、热蒸发烃气相色谱和核磁共振录井资料为例, 介绍3种前期资料处理方法, 1种敏感参数优选的方法, 并介绍了由计算机实现标准化、敏感参数提取的过程, 为后期模式识别方法的建立提供了可靠的基础数据。
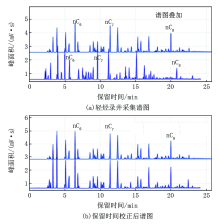
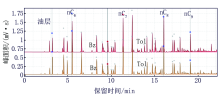
针对轻烃、热蒸发烃气相色谱录井技术进行保留时间校正, 由于考虑不同的设备采集谱图差异性, 单利用谱图直观识别法, 尤其在区分流体界线层易造成结果的错判。整理不同流体性质轻烃谱图96个, 热蒸发烃气相色谱谱图68个, 如果分析谱图为.hw格式文件, 需转换成.txt格式的数据文件导入智能解释软件中, 生成新的谱图文件, 优选3~4个油层标准谱图为代表性样品进行叠加操作[7], 叠加后的谱图由于保留时间不同, 易造成可对比峰视觉偏差(图1a、图2a)。具体操作过程如下:选择资料处理单元里的多点保留时间校正法, 优选3~5个相同组分标志色谱峰对比, 由计算机提取标志峰的保留时间, 通过校正公式[8]计算其差异性, 原始采集谱图的峰面积不变, 计算保留时间一致后由图像表征出来(图1b、图2b), 实现了谱图标准化处理, 使用经保留时间校正处理后的谱图, 可更加直观准确地进行解释分析。
 | 图1 轻烃录井保留时间校正法资料处理效果 |
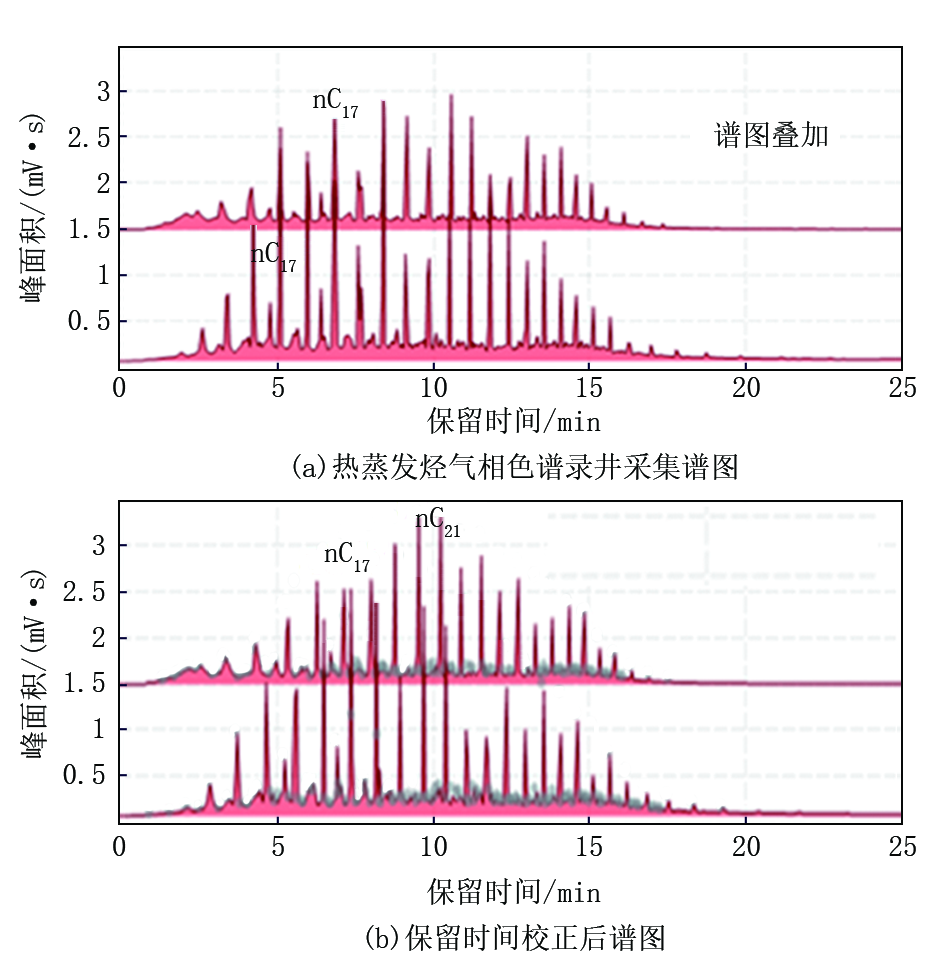 | 图2 热蒸发烃气相色谱录井保留时间校正法资料处理效果 |
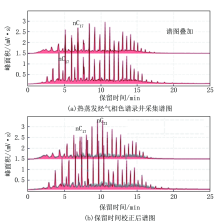
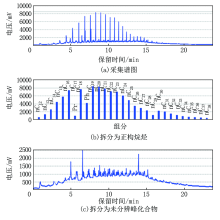
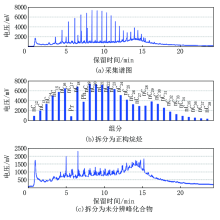
指纹对别资料处理方法主要应用于热蒸发烃气相色谱录井技术, 在区分流体性质识别方面由于油层、油水同层的热蒸发烃组分谱图形态相似, 对油层、油水同层不好区分(图3a、图4a中保留时间校正后谱图肉眼无法准确识别储层为油层还是油水同层), 易造成解释结果的错判。针对该问题, 也查阅借鉴其他油田公司的方法理论, 对热蒸发烃气相色谱谱图需要进行二次处理, 该资料处理方法适用于轻、中质油, 效果明显。由录井智能解释软件中选择资料处理单元(指纹对别法), 将热蒸发烃组分谱图由计算机对正构烷烃和未分辨峰化合物进行分离(图3、图4为拆分效果图), 由计算机观察分离出来的未分辨峰化合物组分峰的谱图, 并重新计算正构烷烃和未分辨峰化合物组分峰的总峰面积, 利用拆分后谱图中组分细微的变化, 达到区分不同流体性质的目的, 含油水层、水层、干层等与油层、油水同层差异性明显, 可不进行再处理。
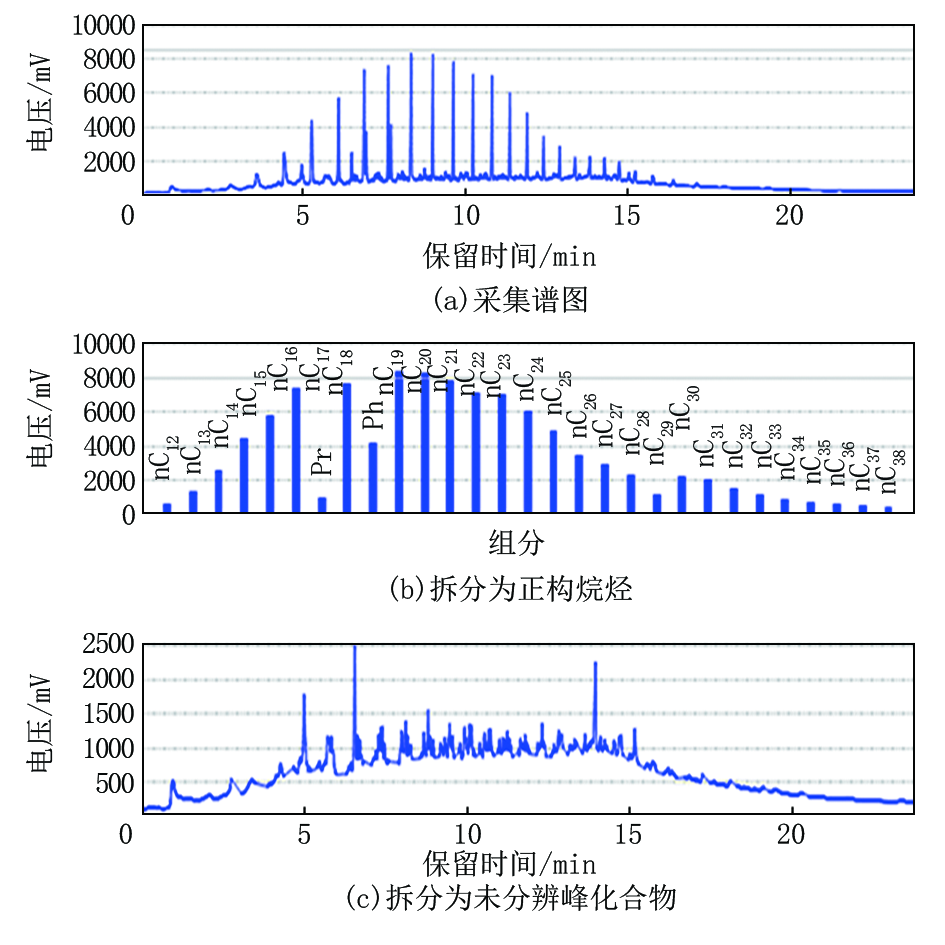 | 图3 油层指纹对别法资料处理效果 |
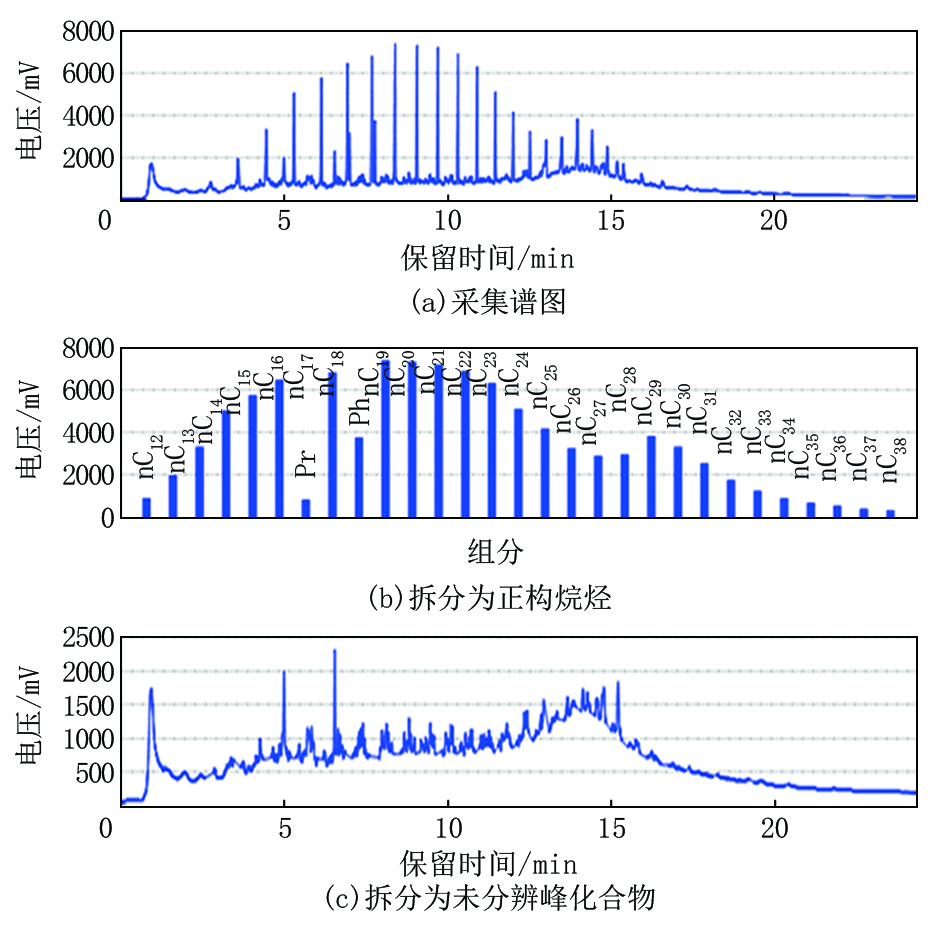 | 图4 油水同层指纹对别法资料处理效果 |
核磁共振T2截止值的选择对储层流体孔隙结构和饱和度计算影响较大, 现场应用一般选取固定的截止值(图5a), 不同地区不同层位截止值不尽相同, 现以长庆油田为例, 通常油探井延安组的截止值为30 ms, 延长组的截止值为10 ms。由于孔隙结构、孔隙大小分布的差异, 可能导致反映流体性质或赋存状态的信息不明显, 为避免T2截止值对核磁共振各项参数的影响, 考虑不选择T2截止值划分常用的固定法、经验法、凹点法、离心法等对储层束缚流体及可动流体进行区分[9], 但如果核磁共振谱图没有T2截止值划分, 求取不同孔隙结构内的流体饱和度均不能实现。为此, 尝试利用核磁共振谱图弛豫时间为横坐标, 建立核磁共振谱图分段方法进行解决。具体实现过程为利用录井智能解释软件选择资料处理单元的谱图重构功能把核磁共振谱图按照横向弛豫时间分为4段(或更多段), 分别为0.1~1 ms、1~10 ms、10~100 ms、100~1 000 ms(图5b), 把重构的谱图利用计算机分别求取与计算0.1~1 ms、1~10 ms、10~100 ms、100~1 000 ms4段时间的含油饱和度(计算方法为划分后10~100 ms区间的油信号强度与总孔隙信号强度的百分比, 其他区间依此类推), 实现定量化, 后期可利用下文智能解释软件敏感参数提取功能对4段时间含油饱和度进行优选, 确定哪部分对产油贡献值大。这种方法能够显著提高资料的准确率, 在核磁录井资料的处理方面也是一种创新的应用尝试。
 | 图5 核磁共振录井技术谱图重构效果 |
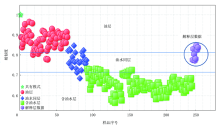
在油气层解释评价过程中, 第一步利用录井智能解释软件资料处理单元, 完成对录井资料的再处理, 实现资料标准化(主要针对谱图采集部分), 第二步需要对敏感参数进行优选(侧重数据采集部分), 由于各单项技术所测得参数有多种, 例如轻烃参数有100多种单组分, 常用的组合参数至少也有10种, 核磁共振录井采集12种参数, 为了准确地选择出能真实反映油气水层特征的敏感参数, 录井智能解释软件主要利用计算机多种算法模型(如ReliefF算法[10])进行敏感参数的提取, 并通过图形化表征结果实现可视化。例如笔者统计轻烃录井、核磁共振录井已经试油的建模数据, 导入录井智能解释软件数据管理单元, 进行敏感参数的提取, 通过分析轻烃录井分类权重较大的参数为总峰面积及重中烃比率(图6), 核磁共振录井分类权重较大的参数为含油饱和度及初始状态可动流体饱和度、初始状态束缚流体饱和度等(图7), 图中PC 1载荷代表每个自变量对主成分的影响程度, 距离越大表示相应参数越敏感, 也就是显示该方法更加直观便捷。
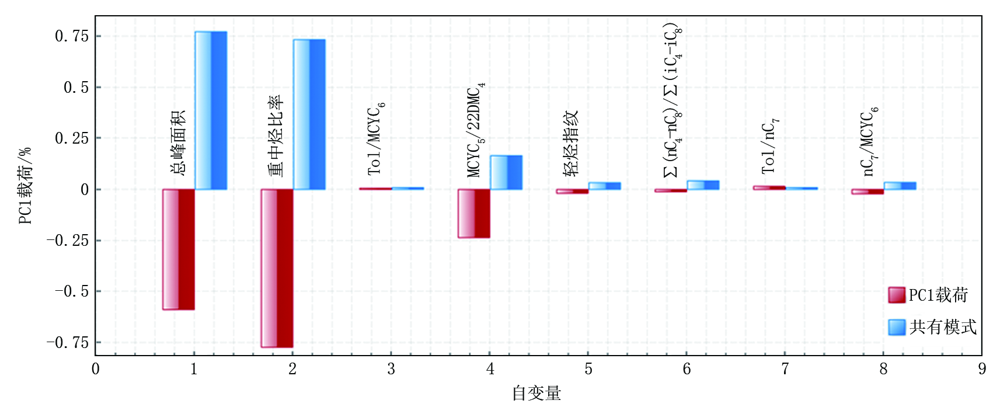 | 图6 轻烃录井技术敏感参数优选 |
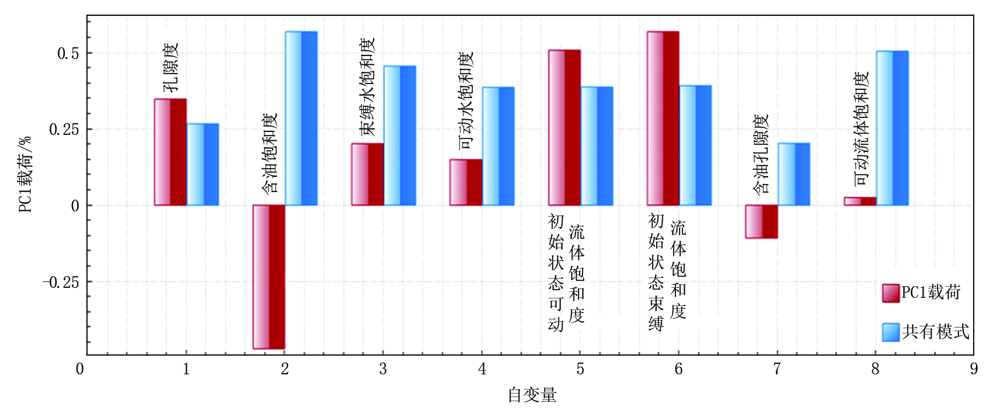 | 图7 核磁共振录井技术敏感参数优选 |
随着录井多种解释模式的建立和积累, 常用的解释模式包括定性识别、定量图板法等, 以及数学模型[11]的产生, 为录井解释向定量化发展提供了简便和有效的途径, 使用数学中的模式识别方法[12]可实现由大数据智能算法代替传统方法对储层解释结果进行预判, 也降低了参与者的主观干扰。在录井智能解释软件中最重要的单元包括模式识别, 一些常用的模式识别技术包括相似度分析、多元统计分析等[13]。
相似度分析主要是利用夹角余弦、相关系数、距离系数等参量计算出样品的差异性, 通过求取各样品的相似度, 实现样品分离的一种方法[14]。以轻烃录井为例, 统计长庆油田试油井不同流体性质轻烃录井数据, 将34个层265个数据导入录井智能解释软件中, 选择模式识别单元的相似度分析(图8采用的是夹角余弦算法)生成图板, 利用新建立图板(数据部分显示或有重合部分)综合分析, 油层、油水同层、含油水层差异性明显。该图板横坐标表示样品序号, 纵坐标表示相似度值, 相似度值大于0.82为油层, 在0.72~0.82之间为油水同层, 小于0.72为含油水层。
 | 图8 轻烃录井相似度解释评价图板 |
录井智能解释软件中模式识别单元最后一部分还包括了多元统计分析。多元统计分析是从经典统计学发展起来的一个分支, 是一种综合分析方法, 它能够在多个对象和多个指标互相关联的情况下分析它们的统计规律[15]。智能解释软件中多元统计分析包含了较多的算法, 如聚类分析、偏最小二乘判别分析、主成分分析、人工神经网络等。本文重点介绍常用的聚类分析、主成分分析两种方法。
2.2.1 聚类分析
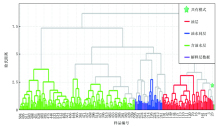
聚类分析是按照“ 物以类聚” 的原则对样品分类的一种多元统计分类方法, 根据相似程度大小把样品进行归类, 并用聚类图表示出来[15]。以核磁共振录井数据为例, 在录井智能解释软件中选择多元统计分析单元的聚类分析算法, 综合分析新生成的图板、分类效果显著, 油层、油水同层、含油水层三组样本各自聚为一类(图9), 浅色线连接代表样本聚类效果差异性相对大小, 横坐标代表样品编号, 纵坐标为欧氏距离。
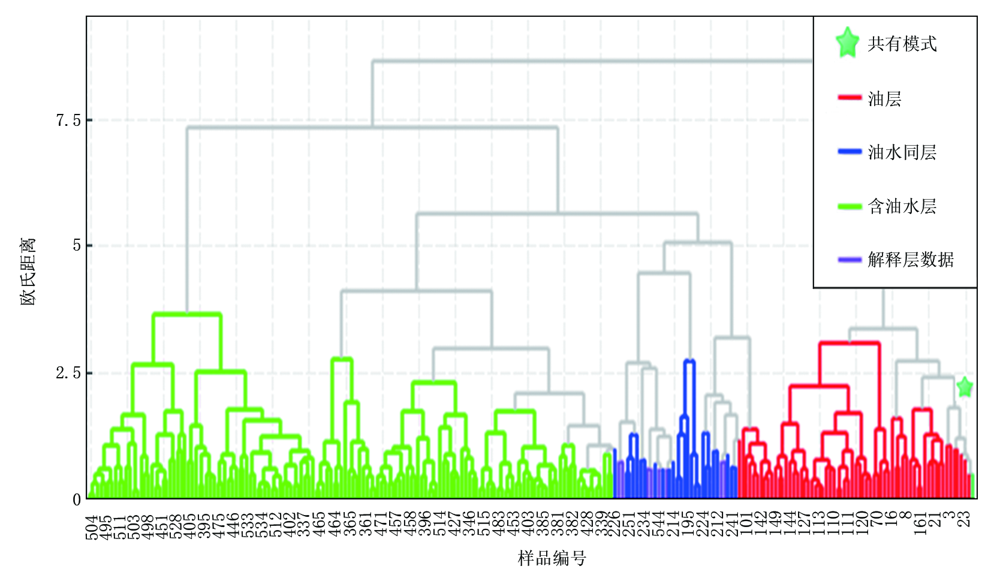 | 图9 核磁共振录井聚类分析图板 |
2.2.2 主成分分析
主成分分析是一种简化数据集的技术, 设法将原来的变量重新组合成一组新的相互无关的几个综合变量, 最后确定其中较少几个主成分作为综合评价指标, 使变量数减少便于实现评估[16]。在录井智能解释软件中选择多元统计分析单元的主成分分析, 横、纵坐标分别用PC得分PC1、PC2表示, PC得分代表自变量所对应的主成分的累计解释方差百分比(图10), 可以看出油层、油水同层、含油水层三组样品也能够自动区分。图10中箭头代表图板的敏感参数, 箭头越长代表该参数在流体性质识别中越敏感, 该图板规律性明显, 可作为后期资料应用。
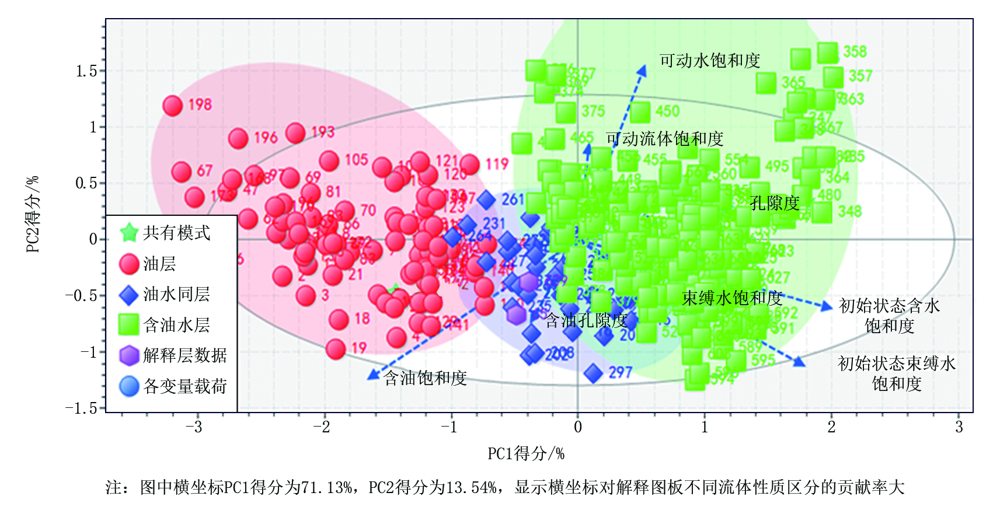 | 图10 核磁共振录井主成分分析判别解释图板 |
为了验证录井资料处理与模式识别技术在解释评价中的应用效果, 通过应用录井智能解释软件对长庆油田15口井66个层进行解释评价, 其中8口井进行测试, 36层符合, 解释符合率为82.35%。本文选择长庆油田油探井B 34井长8段进行详细说明, 便于更好地指导后期生产应用。
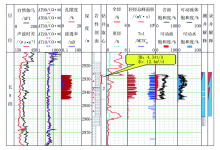
B 34井是环江-镇北区块的一口预探井, 在钻遇长8段井段2 925.0~2 936.17 m时, 含油显示描述为褐灰色原油浸染色, 含油不饱满, 油脂感弱, 不污手, 油味较浓, 含油面积5%~10%, 产状不均匀, 原油无外渗, 岩心新鲜面有潮感, 无咸味, 干后无盐霜, 滴水试验缓渗, 荧光颜色黄色, 荧光面积10%~15%, 产状为不均匀条带状, 点滴试验Ⅱ 级, 系列对比9级, 现场定级为油斑。
电测解释井段2 925.0~2 936.17 m, 电阻率平均值22.94 Ω · m, 自然电位平均值40.09 mV, 孔隙度平均值13.19%, 含油饱和度平均值35.95%, 渗透率平均值0.64 mD, 声波时差平均值225.44 μ s/m。测井结果显示该井段的电阻率一般、物性较好, 解释为含油水层(图11)。
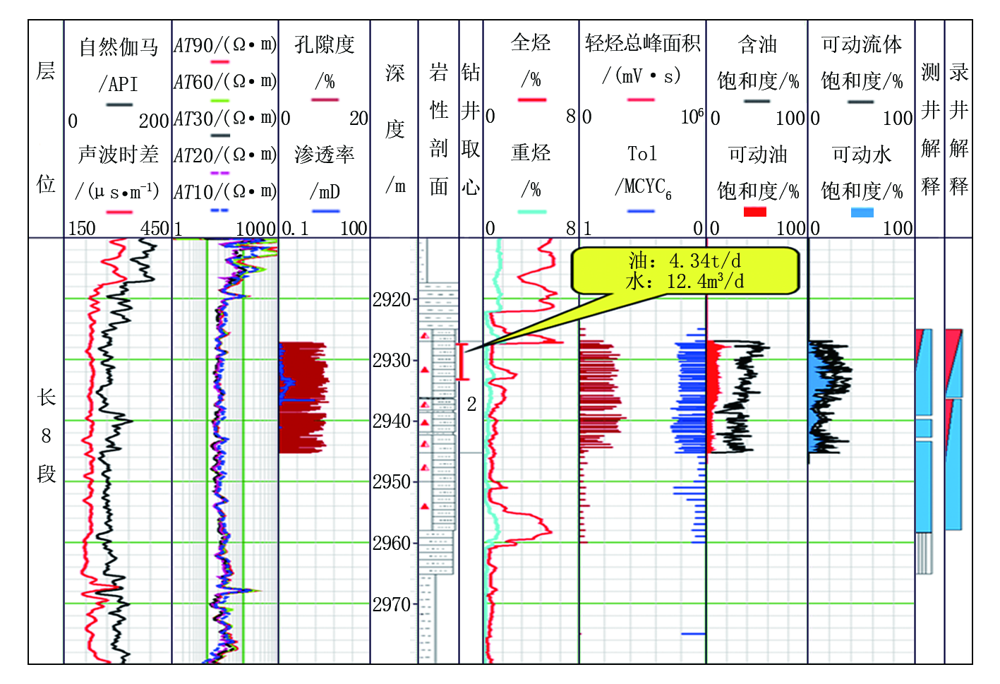 | 图11 B 34井录井综合图 |
该井录井系列为核磁共振录井及轻烃录井技术, 将现场轻烃录井采集谱图文件转换成.txt格式并导入录井智能解释软件中。利用计算机对轻烃谱图进行了保留时间校正处理, 将处理后谱图与建模数据油层谱图进行综合分析可知(图12), 相同组分出峰高低趋势及谱图出峰个数没有明显变化, 含水性的敏感参数芳烃变化也不明显; 轻烃分析数据利用相似度图板(图8解释层数据)分析, 解释数据大部分在油水同层区域, 少部分在油层区域; 多元统计分析中选择了核磁共振录井技术建立的聚类分析及主成分分析图板(图9、图10解释层数据)继续分析, 分析数据均落在油水同层区域。综合分析表明, 计算机模型预测结果给出报告为油水同层, 录井技术建议测试, 最终测试结果本层产油4.34 t/d, 产水12.4 m3/d。
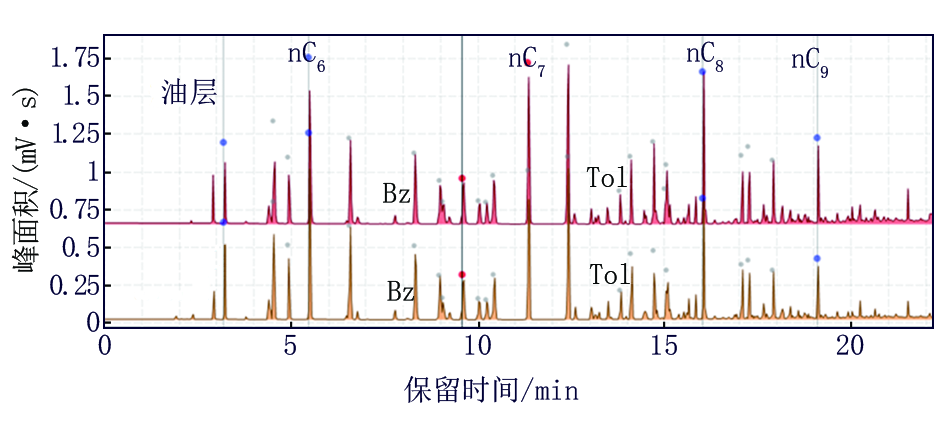 | 图12 B 34井轻烃谱图多点保留时间校正谱图 |
根据生产开发需求研发的录井智能解释软件在资料处理与模式识别方面促进了录井技术向标准化、数字化、智能化方向的发展, 在资料处理方面采用保留时间校正法、指纹对别法、谱图重构法、敏感参数提取等对采集数据进行再处理, 提高了资料利用率; 利用模式识别技术建立了相似度分析、多元统计分析等二维解释评价图板, 充分挖掘了录井资料的应用价值, 后期应用效果也得到了较好验证。随着数据量的增多, 计算机代替传统方法的解释评价模式定会成为日后录井发展新趋势, 该方法的实现具有较高的推广应用价值。
(编辑 王丙寅)
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|