
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于随钻数据的岩性智能识别方法
[邴磊 , 倪朋勃, 张文颖, 杨毅]
, 倪朋勃, 张文颖, 杨毅]
, 倪朋勃, 张文颖, 杨毅]
|
|


作者简介:邴磊 工程师,1974年生,2015年毕业于东北石油大学石油与天然气工程专业,硕士学位,现在中法渤海地质服务有限公司从事录井技术管理工作。通信地址:300450 天津市经济开发区信环西路19号天河科技园1号楼3层。电话:18322056600。E-mail:binglei@cfbgc.com
现场岩性准确识别在油气勘探开发过程中起着至关重要的作用,随着勘探难度增加,现场岩性识别难度也相应加大。针对现场随钻地层岩性识别的难题,提出一种基于随钻数据的岩性智能识别方法,通过对随钻地层元素和钻井参数进行分析,提取特征向量,建立不同岩性的多特征样本库,并用最大最小蚂蚁系统优化算法的广义回归神经网络模型实现了基于随钻数据的岩性智能识别。将该方法应用于实际随钻岩性识别中,对非特征提取数据与特征提取融合数据所构建的MMAS-GRNN模型进行比较,结果表明:基于多源信息特征提取融合数据建立的MMAS-GRNN模型地层岩性识别准确率达到了90.71%,比基于非特征提取数据的模型准确率高出了4.76%,展现出特征提取融合后的多源数据在地层岩性识别效果方面的优越性。
Accurate identification of site lithology plays an important role in oil and gas exploration and development. As the difficulty of exploration increases, the difficulty of lithology identification on site also increases accordingly. An intelligent identification method of lithology based on data while drilling is proposed to solve the problem of on-site stratigraphic lithology identification while drilling. This method analyzes the formation elements and parameters while drilling, extracts the eigenvectors, establishes the multiple-feature collection library of different lithology, and realizes the lithology intelligent identification based on data while drilling by using the generalized regression neural network model of the Max-Min Ant System optimization algorithm.This method is applied to actual lithology identification while drilling, and the MMAS-GRNN model constructed from non-feature extraction data and feature extraction fusion data is compared.The experimental results show that the accuracy rate of stratigraphic lithology identification of MMAS-GRNN model based on multi-source information feature extraction fusion data reaches 90.71%, which is 4.76% higher than that of non-feature extraction data model, showing the superiority of multi-source data after feature extraction fusion in stratigraphic lithology identification effect.
岩性识别是储层评价、油藏描述及现场钻井监测等工作的重要基础。随着人工智能的兴起, 国内外学者对地层岩性智能识别都开展了相关研究。陈溧[1]提出对测井资料进行特征提取, 利用Fuzzy理论对岩性进行判断; 于代国等[2]引入了支持向量机方法(SVM)识别泥岩、砾岩和粉砂岩, 支持向量机有针对性, 训练时间短, 泛化性能好, 能得到全局最优解; Yegireddi等[3]将神经网络和模糊逻辑结合, 建立了自适应模糊神经网络模型, 用于测井数据集的训练测试以识别地层岩性; Konaté 等[4]于2015年利用中国大陆科学钻探主孔(CCSD-MH)测井资料, 将自组织映射神经网络(SOM)应用于变质岩, 最终岩性识别准确率达到了83.25%。但上述研究方法采用的地层岩性识别数据种类过于单一, 无法识别多种岩性的特征, 识别准确度具有一定局限性。
本文在对随钻获得的岩性多源数据进行预处理、相关性分析和特征提取的基础上, 优选最大最小蚂蚁系统优化的广义回归神经网络, 建立了多源信息融合随钻地层岩性智能识别模型, 对基于大量元素录井、随钻钻井参数数据的岩性判识更具有可行性, 降低了人力、物力成本, 提高了地层岩性识别效率和准确率, 进而提升油气钻井作业安全性。
地层岩性差异在随钻数据上的明显响应特征包括两个方面:一是元素含量的差异, 地层岩石由各种不同元素组成, 不同岩性岩石所含元素种类及含量也不同, 可以利用不同含量特征的元素识别地层中不同岩石岩性; 二是钻井参数的变化, 不同岩性岩石的密度、孔隙度、导电性等物理性质不同, 这些物理性质与地层岩石硬度息息相关, 而地层岩石的硬度差异在钻井参数上有响应, 因此可以利用钻井参数来判断识别地层岩石岩性。综合元素含量和钻井参数两类特征对地层岩石岩性进行智能判识。
地层岩石中一般含有Na、Mg、Al、Si、S、K、Ca、Ti、Mn、Fe等主要元素, 以及P、Cl、Ba、V、Ni、Sr、Zr等微量元素。本文研究区为中国南海某凹陷地区构造带, 涉及砂岩、砾岩、泥岩、花岗岩和玄武岩5种岩性。调查发现, 研究区涉及的5种岩性地层中, 不同岩性的地层某些元素含量很接近, 如砂岩、砾岩、玄武岩的Al元素含量比较接近, 砂岩、砾岩、花岗岩、玄武岩的Mn元素含量比较接近, 砾岩、花岗岩、玄武岩的S元素含量比较接近, 所以通过单一元素含量难以对地层岩石岩性进行精确识别, 还需要引入其他参数。
钻井参数一般包括钻时、钻压、转速、扭矩、dc指数、破裂压力等。在本文研究区涉及的5种岩性地层中, 钻时在泥岩中数值明显较大, 钻压在砾岩中数值明显较大, 转速在玄武岩中数值明显较小, 扭矩在玄武岩中数值明显较大; 玄武岩受裂缝条件制约, 通常在裂缝不发育的玄武岩中dc指数数值明显较大, 破裂压力数值也明显较大。
研究区涉及岩性智能识别的数据包括元素数据和钻井参数, 具体为地层岩石中含量大于0.1%的10种主要元素, 即Na、Mg、Al、Si、S、K、Ca、Ti、Mn、Fe数据, 以及钻井过程实时获得的钻时、钻压、转速、扭矩、dc指数、破裂压力6个钻井参数。依据研究区岩性实际情况和研究需要, 将砂岩、砾岩、泥岩、花岗岩和玄武岩岩性分别设置标签为1、2、3、4、5。
为了消除多源数据的差异性、降低数据的维度、减少冗余信息, 凸显数据之间的关系, 本文采用z-score标准化、相关性分析以及主成分分析进行预处理, 得到最终的多特征融合数据。
采用z-score标准化(zero-score normalization)方法对随钻地层岩性多源数据进行标准化归一处理, 旨在将量级不同的多源数据转换到同一个量级, 使多源数据间具有可比性。使用公式(1)-(3)进行z-score标准化处理:
式中:yi为经过转换得到的新数据序列, 其均值为0, 方差为1; xi为多源原数据序列;
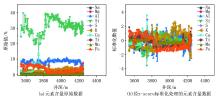
元素含量和钻井参数原始数据与经z-score标准化处理后的数据如图1、图2所示。
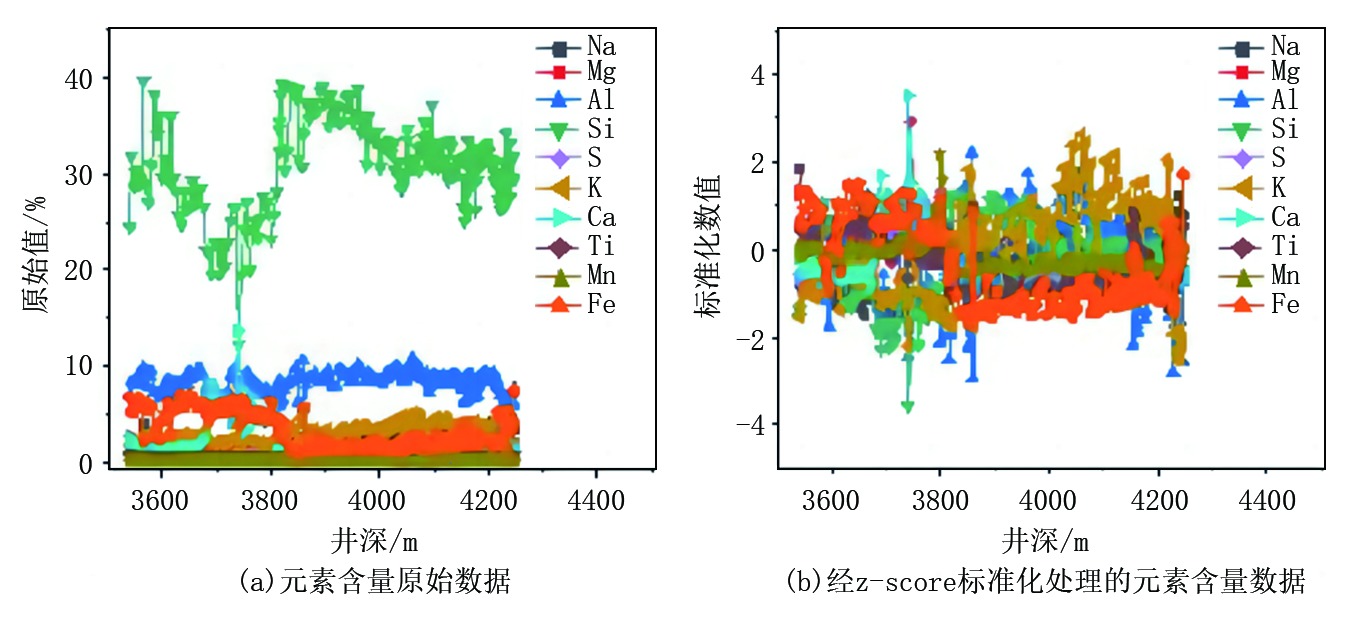 | 图1 地层元素含量原始数据与经z-score标准化处理的数据 |
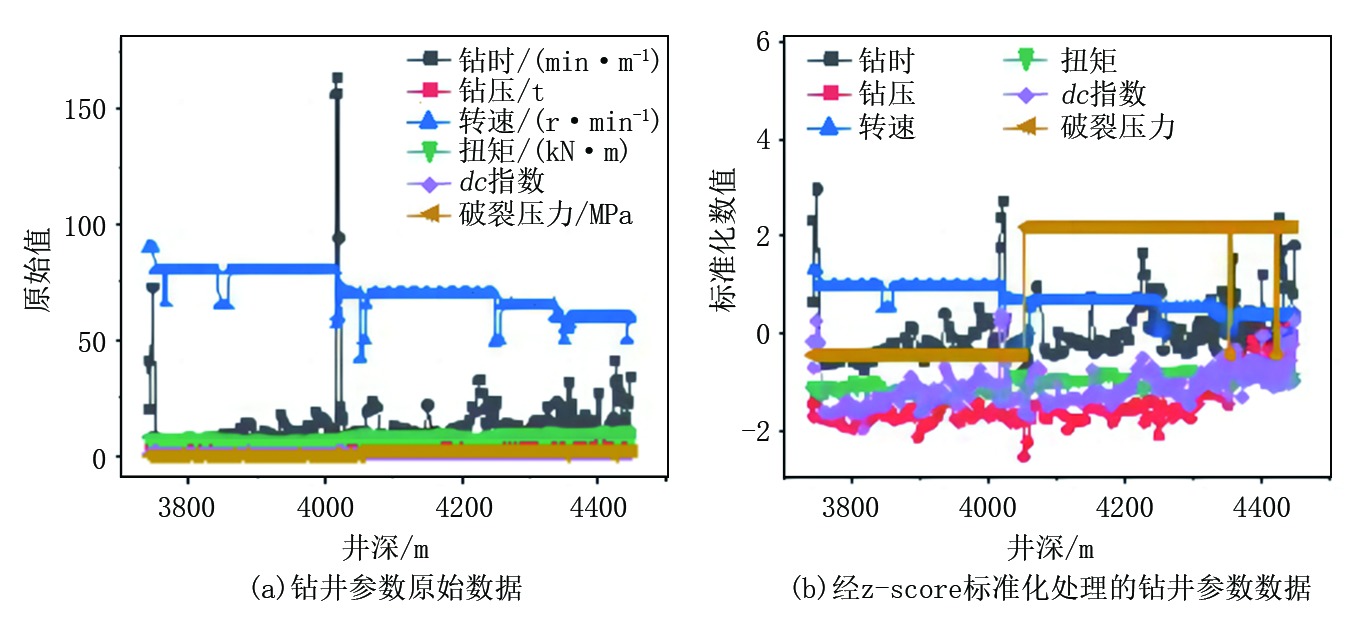 | 图2 钻井参数原始数据与经z-score标准化处理的数据 |
岩性识别时需对上文提到的10个元素数据和6个钻井参数进行优选, 需要一个指标判断多源数据的相关程度。本文使用皮尔逊相关系数分析方法对地层岩性多源数据进行相关性分析[5]。皮尔逊相关系数可以判断两个变量之间是否相关, 该系数取值范围[-1, 1]。X和Y两个变量之间的总体皮尔逊相关系数(
式中:Cov(X, Y)为变量X和变量Y的协方差; Var(X)为变量X的方差; Var(Y)为变量Y的方差。
在研究实际问题时, 数据分析通常是样本分析, 对样本数据做皮尔逊相关性分析得到的相关性系数叫样本皮尔逊相关性系数(rX, Y), 公式为:
式中:
样本皮尔逊相关性系数(
由表1可知, 对研究区随钻地层元素进行相关性分析后可以看出, Mg元素与Si、Ca、Fe元素存在极强的相关性(相关系数在0.8以上), 并且Si元素与Ca、Fe元素之间也存在极强的相关性, 其余部分元素之间也呈现中等程度或较强的相关性。由表2可知, 对钻井参数进行相关性分析后可以看出, 钻时与钻压、dc指数之间存在极强的相关性(相关系数在0.8以上), 并且转速与钻时、指数之间存在较强的相关性。
| 表1 随钻地层元素相关性分析 |
| 表2 随钻地层钻井参数相关性分析 |
综合上述分别对地层元素数据与钻井参数数据进行相关性分析后, 可以得出以下结论:地层元素数据与钻井参数数据内部部分参数之间存在极强的线性关系, 部分参数可以由其他参数线性变换后得到。因此, 16个参数之间存在大量冗余的信息, 为了能够加快模型的训练速度, 需要对这16个参数进行降维处理, 提取数据的关键信息。
主成分分析(PCA)方法能对数据进行压缩并提取数据的特征信息[6], 常用于处理变量维度较高且各变量之间相关性较好的数据。
协方差矩阵特征值对应的单位正交特征向量可以用来表征主成分。按照公式(6)将原变量
上式需满足以下3个条件:
(1)aij是协方差矩阵的各个元素, 相关系数矩阵A是正交矩阵:
(2)主成分Fi、Fj之间相互独立, 两者之间协方差为0, 即:
(3)主成分的重要性
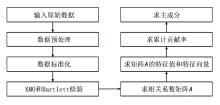
主成分分析流程如图3所示:
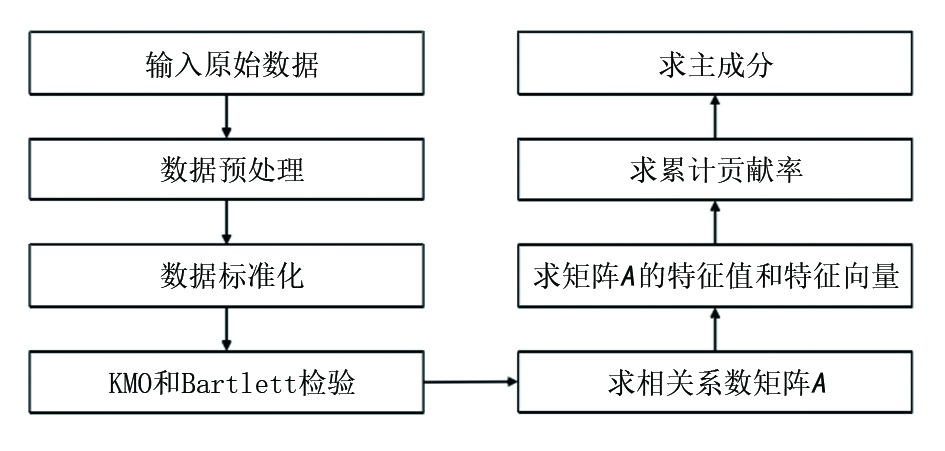 | 图3 主成分分析流程 |
在进行主成分求取之前, 需要对标准化处理后的数据进行KMO和Bartlett检验。KMO检验是用于比较参数变量间简单相关系数与偏相关系数的指标, 取值范围为(0, 1), KMO的值越接近1, 意味着原参数越适合做主成分分析。Bartlett检验是一种检验各个参数变量之间相关性程度的方法, 当统计值的显著性小于0.05时, 说明原参数适合做相关性分析。在本研究中, 将16个参数进行检验, 其中KMO值为0.85, Bartlett检验的显著性小于0.05, 说明这些参数适合进行主成分分析。
之后对研究区的Na、Mg、Al、Si、S、K、Ca、Ti、Mn、Fe、钻时、钻压、转速、扭矩、dc指数、破裂压力16个参数进行主成分分析, 结果如表3所示。
| 表3 元素和钻井参数主成分分析数据结果 |
从表3可以看出, 前5项主成分对数据变异的累积解释比例约为70%(68.433%), 可见提取主成分后, 可纳入原数据信息的70%, 表明用5个主成分可以近似代替原有16个参数, 实现了降维的目标。
在对随钻获得的元素录井参数、钻井参数等进行预处理、相关性分析和主成分分析后, 优选5个主成分来建立地层岩性识别模型。采用最大最小蚂蚁系统优化的广义回归神经网络建立多源信息融合随钻地层岩性智能识别模型, 基于大量元素录井、钻井参数数据对岩性进行判识。
最大最小蚂蚁系统(Max-Min Ant System, MMAS)是Le d-n等[7]基于蚁群优化算法提出的一种改进, 具体改进如下:
(1)改进信息素浓度更新方式。最大最小蚂蚁系统在所有蚂蚁完成遍历迭代后, 只对本次迭代的最优路径上的信息素浓度进行更新, 即可提高蚁群算法收敛速度[8], 公式如下:
τ ij(t+q)=(1-p)τ ij(t)+Δ τ ijbest(t) (10)
式中:τ ij(t+q)为经过q个时刻路径的信息素浓度; (1-p)为信息素轨迹的衰减系数, 为避免路径上轨迹量增加, 取p< 1; τ ij(t)为t时刻属性i的第j个属性项的信息素浓度; Δ τ ijbest(t)为最优路径的信息素浓度; Q为常数, 表示循环一次释放的信息素总量; Lmin为最小环游长度。
(2)限制和设置信息素浓度。将所有路径上的信息素浓度设置在
(3)信息素平滑机制。在算法接近收敛或已经收敛时使用该机制调整信息素, 避免出现算法停滞的现象。公式如下:
τ ij* (t)=τ ij(t)+δ (τ max(t)-τ ij(t)) (12)
式中:τ ij* (t)为调整后的信息素;
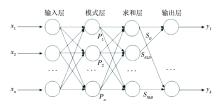
如图4所示, 广义回归神经网络(GRNN)由4层网络组成, 包括输入层、模式层、求和层和输出层。网络训练样本输入维数为N, 输入样本向量可表示为X=[
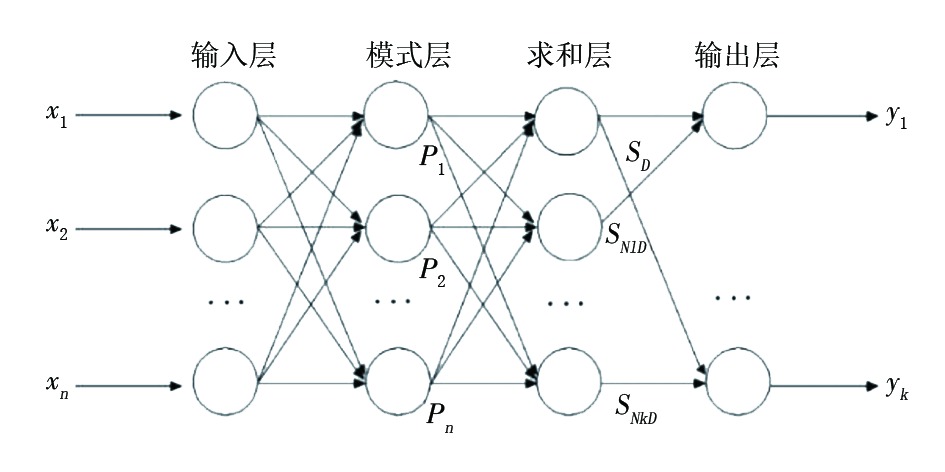 | 图4 广义回归神经网络 |
基于多源信息特征提取融合所构建的MMAS-GRNN随钻地层岩性智能识别模型实现流程如下:
(1)对广义回归神经网络的平滑因子进行范围确定并初始化, 随机生成一个最大最小蚂蚁种群, 并初始化蚂蚁优化算法参数以及最大迭代次数。
(2)将得到的平滑因子的值用于广义回归神经网络训练, 再计算广义回归神经网络的适应度值, 如适应度值能满足最终条件或迭代次数达到最大时, 就终止算法, 反之则继续下一步。
(3)一个最大最小蚂蚁种群对应平滑因子, 让最大最小蚂蚁种群每只蚂蚁选择路径并更新禁忌表, 直到所有蚂蚁遍历完所有路径。
(4)通过蚁周模型更新最佳路径上的信息素浓度并计算遍历之后的最短路径。
(5)重复步骤(2)至(4), 直至满足最终条件。
(6)输出适应度值。
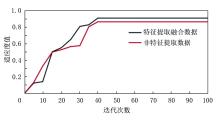
将主成分分析后得到的5个主成分参数作为特征提取融合数据, 而基础的6个参数作为非特征提取数据。基于元素和钻井参数多源信息特征提取融合数据和非特征提取数据所构建的MMAS-GRNN模型的适应度曲线如图5所示。模型初始条件设置:种群规模皆设置为80, 迭代次数设置为100。
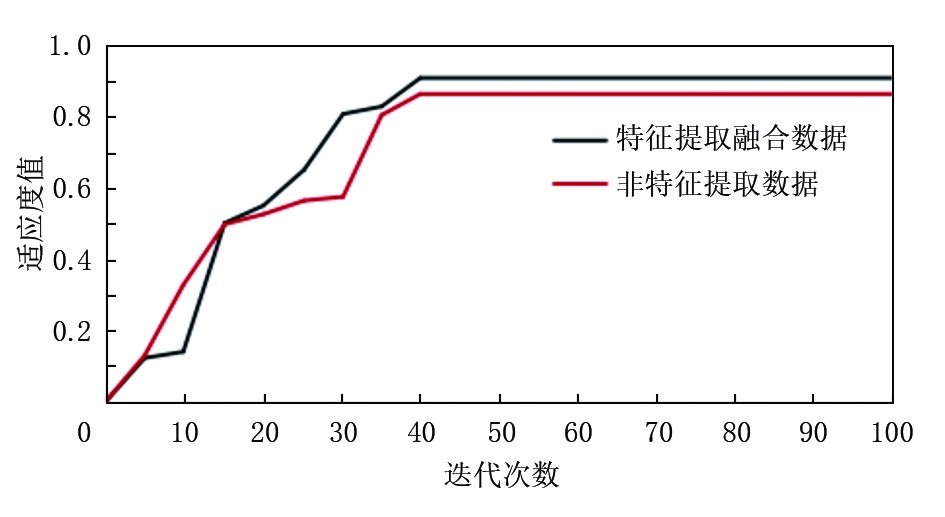 | 图5 MMAS-GRNN模型适应度曲线 |
由图5可知, 在MMAS-GRNN模型的地层岩性识别中, 基于多源信息特征提取数据的适应度曲线相比于非特征提取数据的适应度曲线收敛速度更快、准确率更高, 但两者总体收敛速度相差不大。
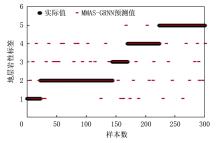
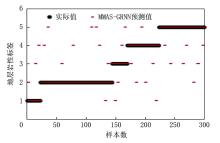
图6、图7分别是基于MMAS-GRNN非特征提取数据和特征提取融合数据的模型应用到实钻井的岩性预测结果, 可以看出, 特征提取融合数据的符合率更高。精确计算后得到:在MMAS-GRNN模型的地层岩性识别中, 基于多源信息特征提取融合数据的地层岩性识别准确率达到了90.71%, 而基于非特征提取数据的地层岩性识别准确率为85.95%。
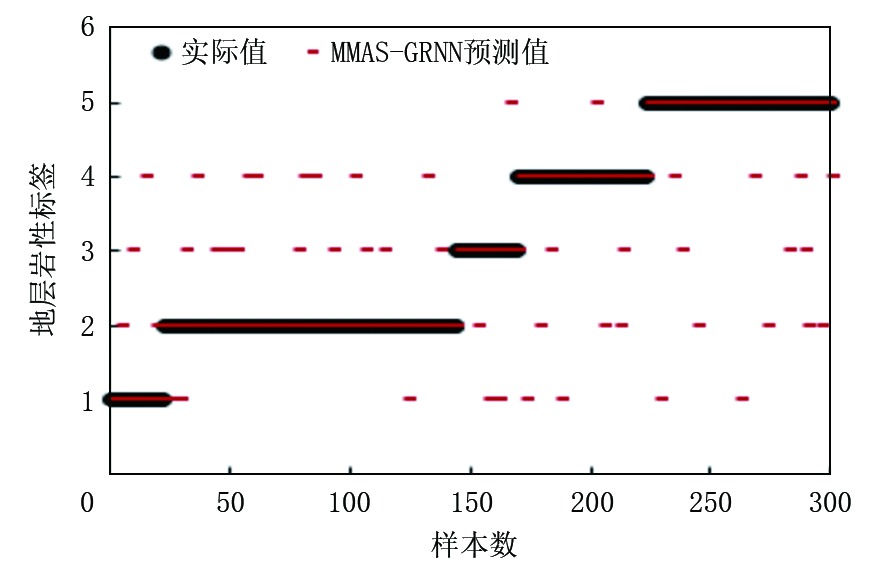 | 图6 MMAS-GRNN非特征提取数据预测结果 |
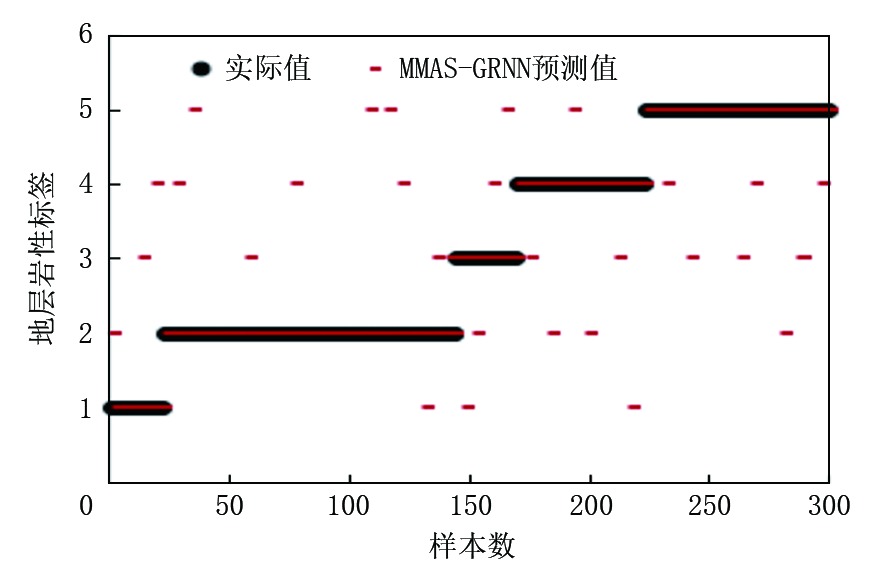 | 图7 MMAS-GRNN特征提取融合数据预测结果 |
本文分析了岩性差异在随钻数据上的响应特征, 通过相关性分析和主成分分析对随钻元素和钻井参数进行多参数特征提取融合, 在此基础上优选MMAS-GRNN系统建立随钻地层岩性智能判识模型, 最终对研究区实钻井进行岩性识别。结果表明:在MMAS-GRNN模型的地层岩性识别中, 基于多源信息特征提取融合数据的岩性识别准确率达到了90.71%, 相对于非特征数据准确率高出了4.76%, 证明多源数据在经过特征提取融合后地层岩性识别效果更理想。
编辑 唐艳军
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|