{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于RBF神经网络模型的天然气储层测录井岩性识别方法
[冯昊楠①, ②, ③  , 杨森
, 杨森③ , 王涛③ , 王依言④ , 曾星海④ , 王方正③ ]
, 杨森|
|


作者简介:冯昊楠 工程师,1996年生,2018年毕业于长江大学地球科学学院资源勘查工程专业,现在中国石油长庆油田公司第三采气厂从事致密砂岩天然气开发地质工作。通信地址:017300 内蒙古自治区鄂尔多斯市乌审旗嘎鲁图镇苏里格气田指挥中心。E-mail:17755401559@163.com
准确确定储层中岩石的类型和特征,可以为天然气勘探和开发提供重要依据,为此研究基于RBF神经网络模型的天然气储层测录井岩性识别方法。该方法针对设备性能差异和人为操作误差等因素导致测录井数据存在的偏差,分别从数据参数转换、压力平衡和钻井液流速影响3方面对测录井数据进行实时校正预处理,运用经验模态分解方法对校正后的测录井数据进行分解,得到低频、高频测录井数据分量,并计算测录井数据不同分量的状态特征谱熵,再将其输入RBF神经网络模型内,经过模型传输、映射和分类,输出天然气储层的岩性识别结果。实验结果表明,该方法可有效对测录井数据实施校正预处理,同时能从测录井数据内分解其高频分量,可准确识别天然气储层的岩性,应用效果较为显著。
Accurately determine the types and characterestics of reservoir rocks and provide an important basis for natural gas exploration and development,this paper,this study investigate a lithological identification method for natural gas reservoirs based on the RBF neural network model using logging data. In order to deal with such factors as equipment performance differences and human operation errors,this paper studies the lithology identification method of natural gas reservoirs based on logging data. After real-time correction and preprocessing of logging data from the three aspects of data parameter conversion,pressure balance,and drilling fluid flow rate,empirical mode decomposition method is used to decompose the corrected logging data,and obtain low-frequency and high-frequency logging data components,and calculate the state characteristic spectral entropy of different components of logging data. Then,the state characteristic spectral entropy is input into the RBF neural network model. After model transmission,mapping,and classification,the lithology identification results of natural gas reservoirs is output. The experimental results show that this method can effectively correct and preprocess logging data,and meanwhile decompose its high-frequency components from logging data,and accurately identify the lithology of natural gas reservoirs. The application effect is significant.
天然气储层的岩性识别不仅关系到天然气勘探的成败, 还直接影响到后续的开发方案和经济效益[1]。因此, 探索和研究天然气储层岩性识别的方法, 对于提高天然气勘探的效率和准确性具有重要意义。天然气储层的岩性识别涉及地质学、地球物理学和石油工程学等多个学科的交叉融合[2]。不同的岩性在物理性质、化学成分和岩石结构等方面存在差异, 这些差异为岩性识别提供了可能。
目前已有的岩性识别方法多存在不足之处。王婷婷等[3]提出储层岩性智能识别方法, 采集储层测井数据后, 将其输入到融合注意力的神经网络模型内, 经过网络模型迭代, 输出储层岩性识别结果。该方法在应用时, 由于测井数据采集过程中容易受压力、钻井液速度等因素影响, 导致测井数据存在偏差, 如果未经过校正处理直接应用, 会导致识别的岩性结果不够准确。Qiu等[4]提出TBM隧道围岩分类识别方法, 采集岩石围岩图像后, 经图像处理技术区分岩石颜色以及状态特征, 运用决策树算法对岩石颜色和状态特征进行分类识别, 得到岩石岩性识别结果。岩石围岩图像的采集质量直接影响后续处理的准确性, 而该方法采集图像分辨率低, 且存在噪声干扰, 直接导致岩石颜色和状态特征的提取不准确, 进而影响岩性识别的精度。李曦等[5]提出粒子群算法优化支持向量机(PSO-SVM)的测井岩性识别方法, 将测井数据输入到支持向量机模型内, 使用粒子群算法对支持向量机模型参数进行优化后, 输出测井岩性识别结果。在测井岩性识别中, 因不同岩性的样本数量可能存在较大差异, 即数据集不平衡, 往往会导致SVM模型在识别样本数量较少的岩性时表现不佳, 从而降低整体识别精度。赵军等[6]提出深度置信网络(DBN)模型的火山岩岩性识别方法, 以薄片鉴定资料为基础, 将其输入到深度置信神经网络内, 神经网络模型通过映射、特征提取等步骤后, 输出岩性分类识别结果。但该方法在应用时, 因深度置信网络模型的复杂度与薄片鉴定资料复杂度不匹配, 容易导致模型出现欠拟合现象, 无法有效学习数据的内在规律, 致使识别精度不足。
测录井数据是石油勘探和开发过程中非常重要的信息来源, 主要用于评估地层性质、预测油气储量等。这些数据通常涉及多种物理参数, 如电阻率、声波速度、自然伽马等, 反映地层的岩石类型、孔隙度、渗透率等关键信息。随着数据科学的快速发展, 数据可视化技术已经成为一种强大的工具, 能够直观、高效地呈现和分析测录井信息。通过测录井数据可视化大屏展示, 石油工程师可以更加快速地识别地层的变化趋势、异常区域以及潜在的油气储层。本文以测录井数据为基础, 提出基于RBF神经网络模型的天然气储层的岩性识别方法, 为天然气开采提供储层的岩性数据。
测录井数据是通过专业的测井仪和录井仪在复杂的野外作业环境中获取的。由于野外环境复杂多变、设备性能存在差异性以及人为操作等因素, 使得测录井数据往往存在一定的偏差。这些偏差不仅影响了数据的精度和可信度, 还可能对后续的油气勘探工作产生误导。
为了消除这些偏差, 引入了录测井影响因素的考虑, 并对测录井数据进行校正预处理。通过综合考虑设备性能、野外环境以及人为操作等多种因素, 采用先进的校正算法对原始数据进行修正, 提高了数据的准确性和可靠性。经过校正后的测录井数据, 能够为油气勘探提供更加准确的依据, 从而优化天然气储层的岩性识别决策过程, 提高勘探效率和经济效益。
1.1.1 数据参数转换
在录井数据的处理中, 为了提升数据的精度并满足更细致的分析需求, 采用插值法将钻深参数间隔从1 m转换成0.1 m。这一转换过程涉及对原始数据的整理与清洗, 为了确保数据的准确性和完整性, 在插值计算时, 根据数据的特征和分析目标, 选择合适的插值类型和插值间隔, 并特别注意处理边界数据, 以确保插值结果的合理性。通过精细的数据参数转换, 能够获得精度更高的录井数据, 为后续的油气勘探和开发工作提供更加可靠的依据。
录井数据参数转换方法为:筛选录井数据集内深度间隔超过0.3 m的相邻数据, 使用上一点深度对应的时间减去下一点深度对应的时间[7], 同时去除停钻时间, 即可得到准确的钻进录井时间, 然后与相邻深度数据的差值相除, 转换成每米钻时, 即可得到录井数据时间参数转换结果T, 公式为:
式中:t1、t2为相邻深度钻进时间; t3为停钻时间; D1、D2为相邻深度值。
使用公式(1)对录井数据的时间参数进行转换后, 依据四舍五入原则, 从录井数据内提取井深间距为0.1 m的录井数据, 再将延迟井深数据恢复到实际深度上, 即可得到步长为0.1 m的连续记录数据。
在测井数据的处理中, 转换过程通常涉及对原始测井数据的解编、校正、插值以及格式转换等步骤。首先, 需要对原始测井数据进行解编, 以提取出各个测井曲线的数值和相关信息。测井数据在采集过程中可能受到多种因素的影响, 如设备性能、野外环境等[8], 因此需要对数据进行校正处理, 以消除这些因素的影响。接下来, 为了获得更高分辨率的测井数据, 需要采用插值方法。与录井数据类似, 测井数据的插值也是基于已知数据点来估算未知数据点的值。假设有两个已知的测井数据点(x1, y1)和(x2, y2), 其中x代表深度, y代表测井曲线的值, 估算一个位于这两个点之间的未知数据点(xi, yi)的值。线性插值的公式可以表示为:
根据两个已知点的数值和给定未知点的x值求解未知点的坐标, 实现测井数据的转换。
1.1.2 压力平衡校正
在获取气测数据时, 天然气储层内的油气会通过地层缝隙流入钻井液内。对于录井而言, 录井仪会依据当前钻井液压力和地层压力计算二者的差。当差值为负数时, 表明录井数据处于欠平衡状态[9, 10, 11]; 当差值为正数时, 则表明录井数据处于过平衡状态。
当钻井液压力小于地层压力时(欠平衡状态), 录井数据校正公式为:
当钻井液压力大于地层压力时(过平衡状态), 录井数据校正公式为:
以上式中:S为校正后的录井数据; S0为初始录井数据; ε 为校正系数。
压力的变化对测井有影响, 这种影响主要体现在地层流体与井筒之间的压力平衡上。在测井过程中, 由于井筒处于静止状态, 地层流体可能会因压力差而缓慢渗入井筒, 从而影响测井仪器测量的井筒压力值。为了得到更接近地层真实压力的数据, 需要进行压力平衡校正。通过采用适合井筒静止状态的校正方法和系数, 可以得到校正后的井筒压力值, 这个值更接近地层的真实压力。校正公式为:
式中:
由此, 更接近地层真实压力的测井数据校正公式为:
式中:Sp为校正后的测井数据; Sp0为初始测井数据。
1.1.3 钻井液流速影响校正
录井气测数据来源于井下返回钻井液, 数值不同则表明天然气储层岩性不同, 在该过程中会使用脱气装置分离钻井液中的油和气。当钻进速度为恒定值时, 单位时间内钻井液流量越大, 则天然气储层岩石破碎产生的油气量越小, 此时录井气测数据数值较低[12]; 反之, 当单位时间内钻井液流量越小, 则天然气储层岩石破碎产生的油气量越大, 此时录井气测数据数值较高。因此, 需要消除钻井液流速对录井气测数据精度的影响, 其校正公式为:
式中:Q为单位时间内钻井液流量; Q1为单位时间内录井仪脱浆量; η 为录井仪脱气装置的脱气效率;
由于测井时井筒静止, 不存在钻井液流速的问题, 测井数据校正不需要考虑钻井液流速的影响。
这表明测井与录井在井筒状态和数据校正方面存在显著差异, 在进行测录井数据校正时, 应充分考虑这些差异, 并采用适合各自特点的校正方法和参数。
1.2.1 经验模态分解方法
运用经验模态分解方法(Empirical Mode Decomposition, EMD)对校正后的测录井数据进行分解, 并描述天然气储层岩性特征, 其详细过程如下。
以校正后的测录井数据为基础, 使用3次样条函数拟合测录井数据得到测录井数据包络线, 找到原始测录井数据集中的极大值和极小值, 使用m1(t)标记测录井数据包络线均值[13], 则测录井数据ϕ 第1个本征模态函数(Intrinsic Mode Functions, IMF)h1(t)表达式为:
h1(t)=S(t)-m1(t) (8)
式中:S(t)为时刻为t时的测录井数据, S(t)∈ ϕ 。
利用公式(8)对原始测录井数据反复运算, 得到满足经验模态分解的条件后, 即可得到测录井数据第1个经验模态分解分量[14], 这里用g1(t)表示, 该分量表示测录井数据内最高频分量。将最高频分量g1(t)从原始测录井数据S(t)中分离, 可得到去掉最高频分量的差值信号, 其表达式为:
r1(t)=S(t)-g1(t) (9)
式中:r1(t)为去掉最高频分量的差值信号。
将公式(9)的结果作为原始测录井数据, 经过重复运算后, 可得到测录井数据的第2个经验模态分解分量, 该分量由g2(t)表示。对上述过程重复运算n次后, 可得到测录井数据的n个经验模态分解分量, 组成经验模态分解分量矩阵, 表达式为:
依据公式(9)、(10)则测录井数据表达式可写为:
式中:
1.2.2 状态特征谱熵计算
经过上述过程得到分解的该测录井数据分量
式中:H为测录井数据经验模态分解分量的空间状态特征谱熵; pj为第j个经验模态分解分量奇异值在所有特征谱中的比重。
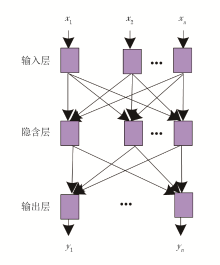
传统捞取砂样识别岩性的方法依赖地质人员的经验和技能, 识别结果可能受到人为判断主观性和操作误差的影响, 且捞取砂样、处理和分析的过程相对繁琐, 需要较长的时间。RBF(Radial Basis Function)神经网络模型在处理非线性问题时具有出色的性能。将获得的测录井数据作为输入项(包括电阻率、声波速度、自然电位、钻井液参数、钻时和钻速等), 由RBF神经网络自动输出岩性识别结果, 减少了人为因素的干扰, 从而获得更为精准的结果。RBF神经网络模型结构如图1所示。
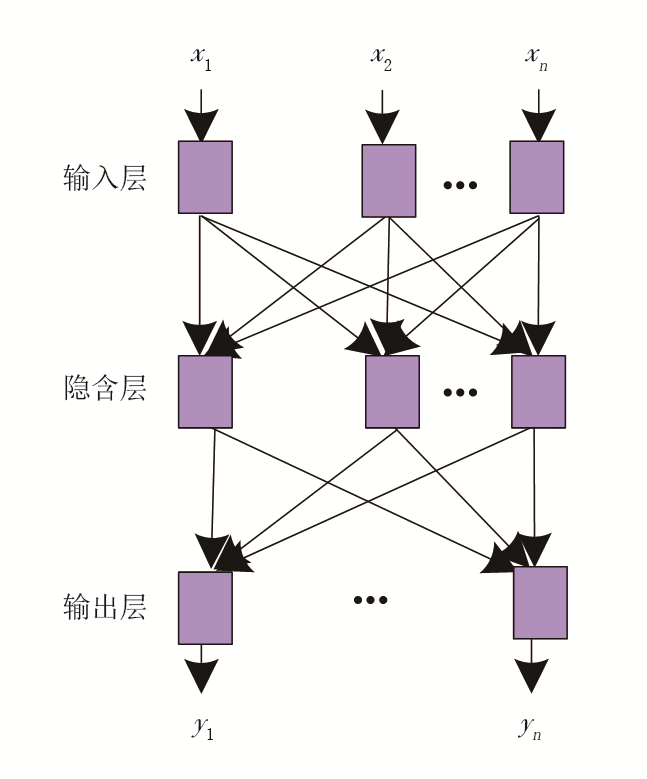 | 图1 RBF神经网络模型结构 |
运用RBF神经网络模型识别天然气储层岩性详细过程如下。
(1)将1.2.2小节得到的测录井数据状态特征谱熵作为输入, 建立RBF神经网络模型输入样本, 由
Zμ =H′ Wμ (13)
式中:Wμ 为第μ 个神经元输入层与隐含层的连接权值。
(2)以公式(13)的输入为基础, RBF神经网络模型传递测录井数据状态特征谱熵时的传递函数Γ (Zμ )表达式为:
式中:λ 为平滑参数。
(3)经过传递函数传递测录井数据状态特征谱熵后, 将其输入到隐含层内, 该层使用基函数捕捉测录井数据状态特征谱熵的特定特征, 其表达式为:
式中:
(4)以上述各式为基础, RBF神经网络模型识别天然气储层岩性结果yμ 表达式为:
式中:m为隐含层总数。
以我国X盆地作为实验对象, 该盆地拥有极为丰富的岩层构造, 盆地底部沉积了古生代形成的灰色泥质灰岩和白云岩, 这些岩石在海洋沉积环境中形成, 富含丰富的古生物化石。中新生代的岩层逐渐占据主导, 其中夹杂着大量的粉砂岩、泥岩和碳质页岩, 反映了盆地由海洋向内陆的演化过程。盆地中部, 岩石类型更加多样, 包括灰色、褐灰色的泥粉晶白云岩, 富含碳酸盐矿物, 形成了独特的岩溶地貌。此外, 还有大量的灰黄色薄层瘤状细晶白云岩, 这些岩石在沉积过程中经历了复杂的物理化学作用, 形成了独特的结构和纹理。在盆地的上部, 岩石类型以砂屑-砾屑白云岩和藻纹层白云岩为主, 这些岩石记录了盆地内湖泊和河流的沉积历史。这些岩石中还夹有黑色页岩条带和沥青质页岩, 这些富含有机质的岩石是盆地内油气资源的重要来源。
综上, X盆地的岩层类型丰富多样, 从海洋沉积的灰岩、白云岩, 到内陆湖泊、河流沉积的粉砂岩、泥岩, 再到富含有机质的页岩和碳酸盐岩, 共同构成了盆地独特的地质景观, 其中也蕴含着丰富的油气资源。可运用本文提出的RBF神经网络方法对该盆地内天然气储层岩性进行识别处理, 为天然气开采提供岩石岩性数据。
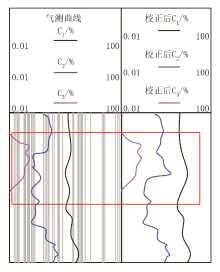
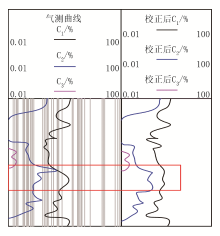
本文利用测录井仪器获取到X盆地天然气储层测录井数据。以任意两条录井数据作为实验对象, 这两条录井数据分别存在过平衡状态和欠平衡状态, 校正后的结果如图2、图3所示。
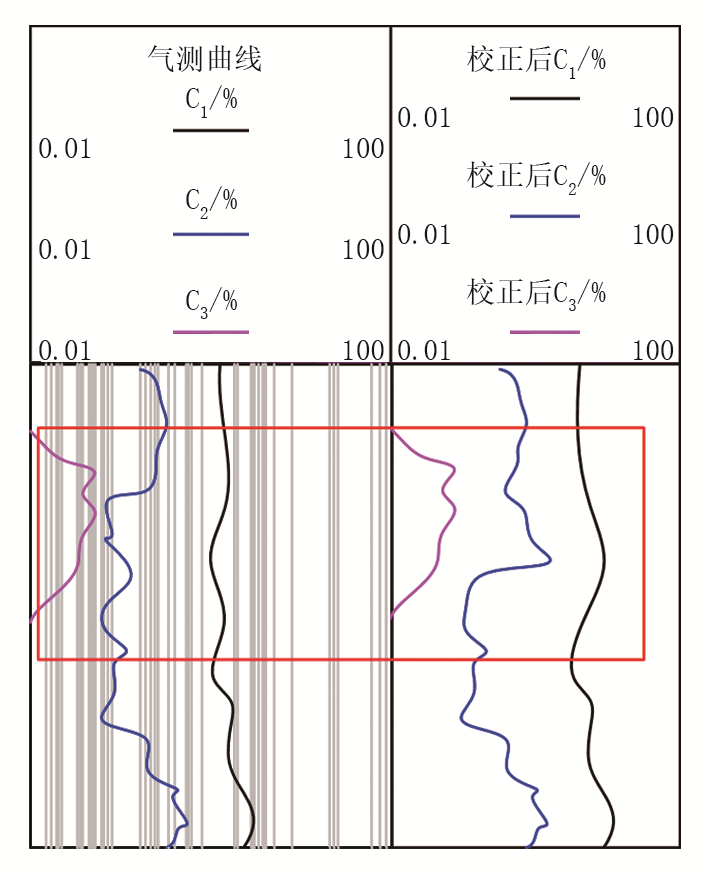 | 图2 过平衡状态校正 |
 | 图3 欠平衡状态校正 |
由图2、图3可知, 录井数据在过平衡状态和欠平衡状态下, 校正前的气测曲线数值均偏离初始值, 经过本文方法对这些异常数据进行校正后, 在红色标记框内的气测曲线数值均接近于初始值。这一结果表明, 该方法具有录井数据平衡校正能力, 能够显著提高数据的准确性和可靠性, 为后续的天然气储层岩性识别提供了准确可靠的录井数据支持。
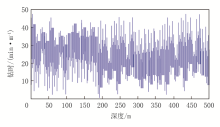
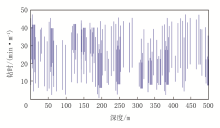
以录井数据中的钻时数据作为实验对象, 使用RBF神经网络方法对其进行经验模态分解处理, 获取其高频分量, 结果如图4、图5所示。
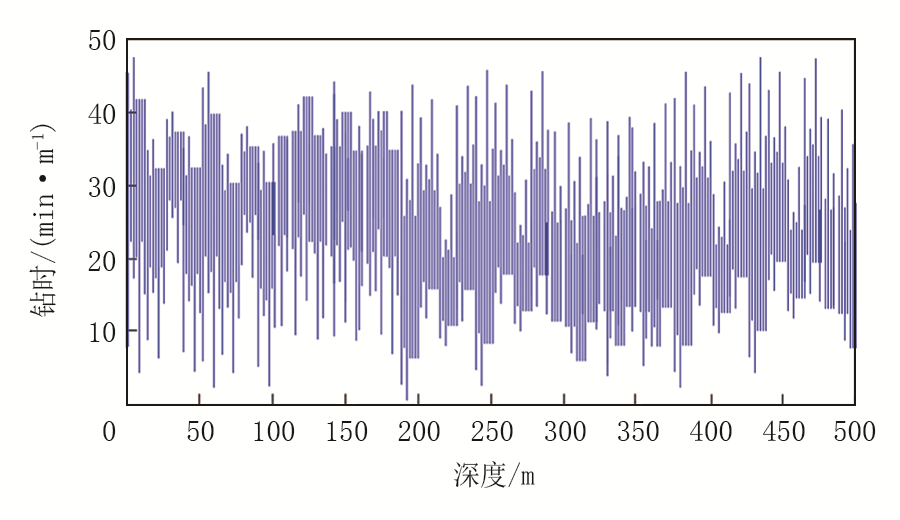 | 图4 原始钻时结果 |
 | 图5 钻时高频分量结果 |
综合分析可知, 运用RBF神经网络方法可有效对测录井数据进行经验模态分解, 从原始的钻时曲线内获得高频分量, 为后续计算天然气储层岩性空间状态特征谱熵打下良好基础。
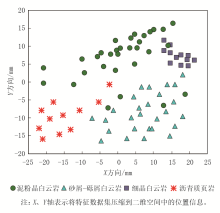
在X盆地某区域的天然气储层研究中, 选择关键的测录井数据进行EMD处理, 以应用于岩性识别。将电阻率、声波速度、自然电位等测井数据, 以及钻井液密度、钻井液含气量等录井数据作为输入, 通过EMD方法, 将这些能够反映地层的测录井数据分解成若干个IMF, 每个IMF代表了数据在不同频率段上的特征。计算这些IMF的谱熵, 反映数据的复杂性和不确定性, 以量化不同天然气储层岩性空间状态的特征。将计算得到的谱熵以二维投影图的方式呈现出来, 以便直观地观察和分析不同天然气储层岩性的空间分布特征, 如图6所示。RBF神经网络方法能够精准计算天然气储层岩性的空间状态特征谱熵, 通过二维投影, 直观展现不同岩性空间状态特征谱熵的分布, 为天然气储层岩性识别提供强有力的特征分析依据。这一成果不仅增强了数据解析能力, 还提升了岩性识别的效率和准确性。
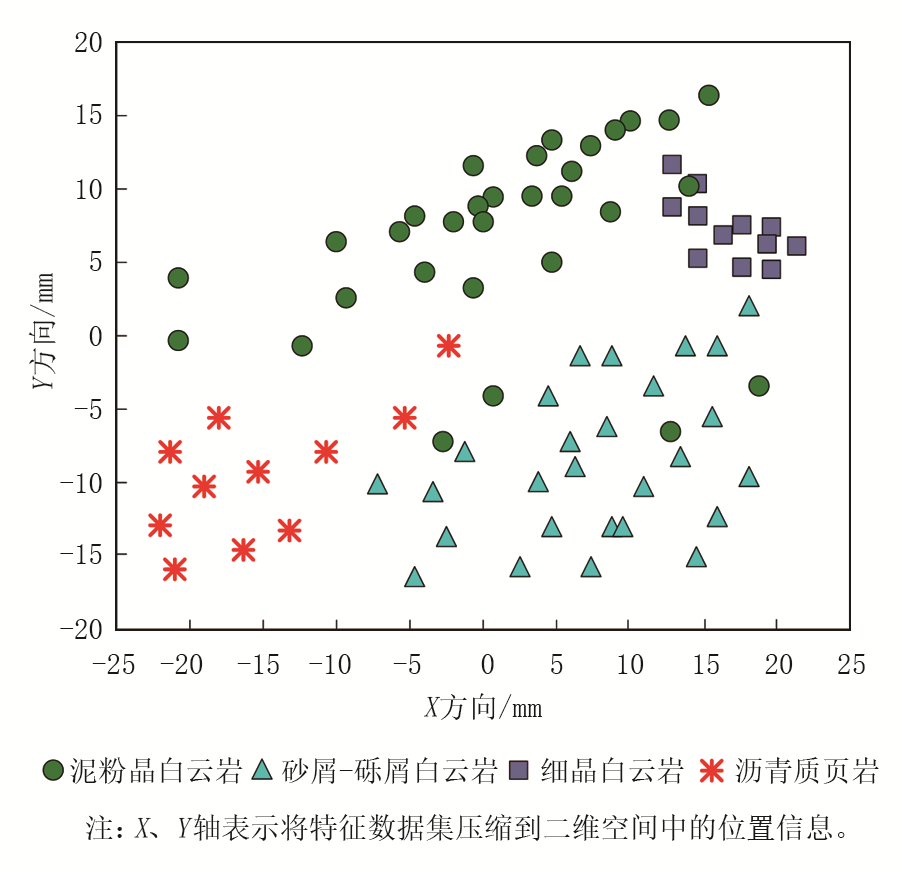 | 图6 天然气储层岩性空间状态特征谱熵 |
将天然气储层岩性空间状态特征谱熵输入到RBF神经网络模型内, 通过模型迭代输出天然气储层岩性结果, 以X盆地某区域作为实验对象, 使用本文方法识别该区域天然气储层岩性, 识别结果如表1所示。经过对表1深入分析可以清晰地看到, 在识别天然气储层不同埋藏深度的岩石岩性方面, RBF神经网络方法不仅精确度高, 而且操作性强, 为天然气开采实施提供了有力的技术支持。在实际应用中, 用户可以根据岩石的不同岩性选择合适的开采方式, 从而提高开采效率和安全性。
| 表1 天然气储层岩性识别结果 |
为进一步验证RBF神经网络方法识别天然气储层岩性的能力, 给出5种不同岩性类型天然气储层的测录井数据共600个, 使用RBF神经网络方法识别这600个测录井数据中不同的岩性类型, 识别结果如表2所示。
| 表2 天然气储层岩性识别数量 |
分析表2可知, 在600个测录井数据中, RBF神经网络方法识别长石砂岩、泥质砂岩和沥青质页岩时, 其识别错误数量均为0, 识别泥晶灰岩和碳酸盐岩时的错误数量分别为2个和1个。从精度上来讲, RBF神经网络方法识别天然气储层岩性的精度高达0.995, 说明RBF神经网络方法具备精准的天然气储层岩性识别能力。
在天然气勘探领域中, 基于RBF神经网络模型的天然气储层测录井岩性识别方法从应用角度展现出其独特的重要性和深远影响。这种方法不仅为勘探人员提供了直观、准确的地下岩层信息, 而且在实际应用中展现出极高的灵活性和适应性。
从应用角度看, 基于测录井数据的岩性识别方法能够显著提升勘探效率。通过对测录井数据的深入分析, 勘探人员能够快速识别天然气储层的岩性特征, 进而确定勘探重点区域, 可极大地缩短勘探周期, 降低勘探成本, 使天然气勘探更加经济高效。
此外, 该方法还能为天然气开发提供重要参考。通过对不同岩性储层物理特性和化学组成的研究, 可以更准确地评估储层的产能和开采潜力, 为制定合理的开发方案提供科学依据, 对于保障天然气资源的可持续利用、满足社会对清洁能源的需求具有重要意义。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|