{kind=link}
{kind=link}
{kind=link}
{kind=link}
机器学习建模及其在气测录井解释中的应用
[姚金志①  , 杜焕福
, 杜焕福① , 侯文辉① , 吴会昕② , 陈栋① , 曹绍华② ]
, 杜焕福|
|


作者简介:姚金志 高级工程师,1969年生,1991年毕业于南京大学古生物学及地层学专业,现在中石化经纬有限公司地质测控技术研究院从事装备研发和产品产业化工作。通信地址:257000 山东省东营市东营区乐园路1号。E-mail:yaojzh6.osjw@sinopec.com
随着油气勘探开发的深入,以图板为主的传统气测录井解释方法难以满足复杂储层与油气水关系的评价需求,近年来大数据分析和机器学习的快速发展为气测录井解释提供了新的方向。基于多口井的气测解释数据,应用数据预处理与特征工程方法对气测数据进行处理,并采用5个常用的机器学习模型(KNN、NB、SVM、MLP、LightGBM)进行建模解释与应用对比分析,结果表明,SVM与LightGBM模型综合表现较好,平均预测准确率达到87%以上,能够满足实际的解释需要。机器学习模型解决了传统解释图板灵活性不足,受维度限制难以提取深层信息等问题,显著提升了解释准确率,具有实际推广应用价值。
With the deepening of oil and gas exploration and development, the traditional gas logging interpretation methods mainly based on charts are unable to meet the evaluation needs of the relationships between the complex reservoirs and oil, gas and water. In recent years, the rapid development of big data analysis and machine learning has provided a new direction for gas logging interpretation. Based on gas logging interpretation data from multiple wells, data preprocessing and feature engineering methods are applied to process the gas logging data, and five common machine learning models (KNN, NB, SVM, MLP, LightGBM) are used for modeling interpretation,application,comparison and analysis. The results show that the comprehensive performance of SVM and LightGBM models is good with an average prediction accuracy of over 87%, which can meet the actual interpretation needs. The machine learning model solves the problems of the insufficient flexibility of the traditional interpretation charts and the difficulty of extracting deep information due to the dimensional limitations, and significantly improves the interpretation accuracy, which has the practical value of promotion and application.
录井技术是油气勘探开发中的一项重要技术, 是发现评估油气藏最及时、最直接的手段。该技术通过地球化学、地球物理等方法, 对钻井过程中的各种地质数据进行采集、记录和分析, 以帮助石油勘探开发人员了解地层情况、评估油气储层, 并为石油工程提供钻井信息服务, 对于确定地层岩性、含油气性及制定油田开发方案等都具有重要意义[1]。气测录井是录井技术的重要分支, 通过收集、分析钻井过程中的气态烃组分数据, 包括甲烷(C1)、乙烷(C2)、丙烷(C3)、正丁烷(nC4)、异丁烷(iC4)、正戊烷(nC5)、异戊烷(iC5), 对目标地层流体性质(油层、气层、水层等)进行识别分类。然而, 传统气测录井解释方法主要依靠解释图板与解释模型, 过度依赖人工经验, 并且模型参数较为单一, 不能充分挖掘数据中的隐含信息[2], 其解释准确性有时无法满足复杂储层与油气水关系下的评价需求[3]。而近几年大数据分析和机器学习的快速发展, 为解决该问题提供了新的思路。
机器学习是人工智能的分支领域, 通过让计算机从大量历史数据中学习, 挖掘隐藏其中的模式和规律, 实现自主学习和决策。将机器学习算法引入录井领域, 可以充分挖掘录井数据隐含的信息, 提高解释效率与准确率, 从而提升油气勘探效益。目前机器学习已在岩性识别、地质导向、工程预警、流体识别等领域开展相关研究[4]。杜克拯等[5]利用BP神经网络研究气测录井资料定量解释方法, 优化参数选择与储存流体性质判别项, 取得较好的解释效果; 万康等[6]使用模糊神经网络技术对入井各项参数进行动态监控, 实现工程异常的快速准确识别与预报, 降低事故损失; 唐诚等[7]在页岩气评价中优选SVM、神经网络等多种机器学习算法, 获得较好的元素参数拟合效果; 沈文建等[8]应用大数据分析技术处理地化录井数据, 通过训练决策树模型完成原油性质分类; 李春生等[9]提出基于数据挖掘的录井剖面归位解释方法, 通过数据清洗、特征工程选取有效数据特征, 并使用神经网络进行建模, 平均识别率达到92%; Yang等[10]提出基于高斯过程模型的气油比预测方法, 利用钻井液的气体数据有效降低了预测的误差。
尽管机器学习方法在录井领域的应用有了一定发展, 但在气测录井领域的研究仍然较少, 缺乏对不同机器学习模型效果的系统对比, 同时现有研究整体建模流程并不完善, 多数直接使用原始数据进行建模而忽略了数据处理和特征工程环节, 难以获得最优模型。为此, 本文进一步探究机器学习在气测录井领域的应用。首先构建完整的机器学习建模流程; 其次针对气测录井流体性质分类任务的特点, 设计数据预处理与特征工程方法, 包括对气测数据进行过采样增强、构建气测图板相关特征等, 同时通过搜索模型最优超参数设置以进一步增强模型性能; 然后应用多种机器学习方法建模并分析预测结果; 最后通过消融实验验证本文建模方法的有效性。
虽然近年来深度学习技术有了较大的发展, 但已有研究表明[11, 12, 13], 传统统计机器学习模型在气测录井表格类数据上比深度机器学习模型有更好的表现。此外, 由于录井任务自身数据量较少, 难以支持深度机器学习模型的训练, 因此本文主要关注传统统计机器学习模型在气测录井领域的应用。
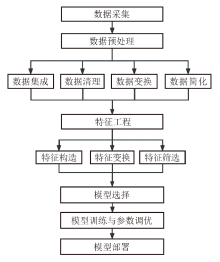
传统统计机器学习建模通常包含数据采集、数据预处理、特征工程、模型选择、模型训练与参数调优、模型部署等步骤, 传统统计机器学习建模基本流程如图1所示, 其中数据预处理与特征工程是建模的关键环节。对于气测录井解释任务而言, 需要结合录井解释相关的专业知识, 采用合适的数据处理方式与特征工程方法以提高模型预测精度。
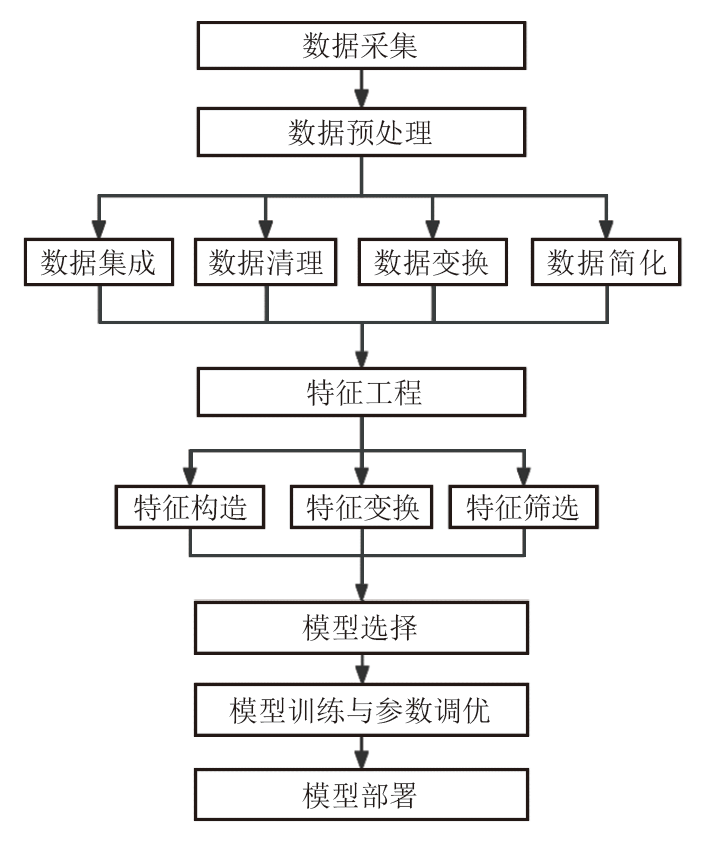 | 图1 传统统计机器学习建模基本流程 |
数据预处理是数据分析与机器学习建模中的重要步骤, 通过数据集成、清理、变换和简化4步操作[14]以提高后续模型建立与分析的可靠性和准确性。其中, 数据集成主要是对多个数据源进行合并处理, 如合并提供相同数据的不同数据库或文件, 解决不同数据库或文件中数据重复、冲突和不一致等问题; 数据清理主要是处理无关数据与异常值, 如删除重复值、异常值, 填补缺失值等; 数据变换主要是通过数据提取、变换找到合适的数据表示方式; 数据简化主要是提取数据中的有用信息, 剔除冗余、无用数据, 简化数据结构。
在构建气测录井训练数据集时, 通常涉及某一区域多口井的数据, 首先要将不同井的数据进行集成, 统一多口井数据特征并合并到一个数据表中。在气测数据的采集过程中经常由于多种原因导致数据组分缺失, 因此在数据清理步骤中主要关注缺失值处理, 常用的处理方式包括删除、填补。此外, 气测解释数据通常存在样本量小且类别分析不均衡问题, 机器学习模型可能会偏向于占主导地位的类别而导致模型性能下降, 在实际处理过程中通常使用数据过采样方法缓解该问题, 其中合成少数类过采样(SMOTE)[15]是一种被广泛应用的技术, 通过合成少数类样本增加其在数据集中的数量以实现样本平衡。
特征工程在机器学习任务中具有至关重要的作用, 通过对原始数据进行变换、组合、选择等操作, 从中提取更有信息量和表达能力的特征, 进而提升模型性能和泛化能力。其常用的操作方法包括特征构造、特征变换与特征筛选。
1.2.1 特征构造
特征构造是通过对原始特征进行组合、衍生等操作, 生成新的特征来增强模型的展示能力和预测性能的技术。特征构造方法通常利用与任务相关的专业知识, 从数据中挖掘潜在的信息和模式, 从而更好地捕捉变量与预测目标之间的关系。传统的气测解释图板中常用特征构造方法来构造湿度比、特征比、平衡比等指标作为坐标, 从而提高图板分类效果。对于机器学习来说, 特征构造对预测性能提升具有重要作用。
1.2.2 特征变换
特征变换是通过对原始特征进行转换, 生成更具表达能力与适应性新特征的技术, 常用的方法包括数据标准化、归一化、离散化、特征编码等。数据标准化与归一化旨在消除特征间的量纲影响, 使得不同特征具有可比性; 离散化将连续数据转换为离散的类别或区间, 以简化数据结构, 同时消除无关细节; 特征编码能够将非数值特征(如类别、文本标签)转化为数值形式以适配模型的输入要求。对于气测解释任务, 数据在输入模型之前通常需进行归一化操作以提高模型精度和稳定性。
1.2.3 特征筛选
特征筛选是通过对特征的重要性进行评估和排序, 筛选最具代表性和预测能力的特征子集, 从而提高模型的性能和效果的技术[16]。其常用的方法为嵌入法, 即先使用某些机器学习算法和模型进行训练, 得到各个特征的权值系数, 根据权值系数从大到小选择特征。
在模型选择阶段, 需要根据数据特性和任务需求选择合适的模型, 目前较常用的机器学习模型包括KNN(K近邻算法)、NB(朴素贝叶斯)、SVM(支持向量机)、MLP(多层感知)以及LightGBM(轻量梯度提升机), 各个模型的核心原理和优缺点如表1所示。
| 表1 常用机器学习模型核心原理和优缺点 |
在完成数据预处理与模型选择后, 即可进行模型训练。首先创建模型实例, 初始化模型超参数, 然后利用数据集和优化算法迭代调整模型参数, 最小化预测损失, 最终学习得到从输入数据到输出结论的映射关系。模型创建、训练过程通常由软件工具包(如scikit-learn)自动完成, 而模型超参数则需要根据任务实际需求手动设置, 为了使模型具有最佳的预测性能, 有必要对模型超参数进行调整优化。目前, 基于贝叶斯优化[17]的网格搜索方法被广泛使用。网格搜索是一种暴力调参方法, 通过遍历所有可能的参数组合来找出其中最优的参数组合, 应用贝叶斯优化的网格搜索方法会在测试一个新的数据点时考虑前一个数据点的信息, 通过建立概率模型来预测目标函数值, 并使用采集函数来确定下一个要测试的数据点, 以便能够在有限的样本数量下得到相对较好的结果。在搜索到最优超参数设置后, 需要使用该参数在数据集上再次训练以获得最终模型。
模型部署用于实现现有模型的复用。一个训练良好的模型通常能够适应某个或多个工区的数据特征, 因此能够重复利用该模型进行预测和解释, 无需再次训练模型。在保存模型文件的同时也需保存数据处理的步骤和操作, 以便进行模型部署应用。
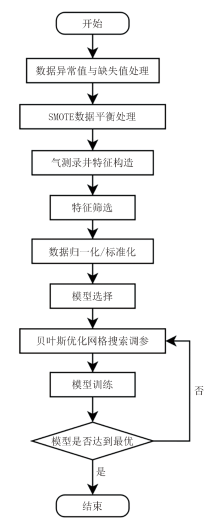
基于上文所述数据预处理与建模方法, 本文设计了气测录井解释机器学习建模流程(图2)。在数据预处理阶段, 首先对采集的气测数据异常值和缺失值进行处理, 然后根据数据分布情况采用SMOTE算法平衡样本; 在特征工程阶段主要构造与气测录井相关的特征, 并通过特征筛选保留重要性较高的特征作为模型输入; 在模型训练前, 对输入特征进行标准化或归一化操作以提高模型效果; 选择模型后, 在训练阶段通过基于贝叶斯优化的网格搜索方法调整模型参数以获得最优的模型效果。
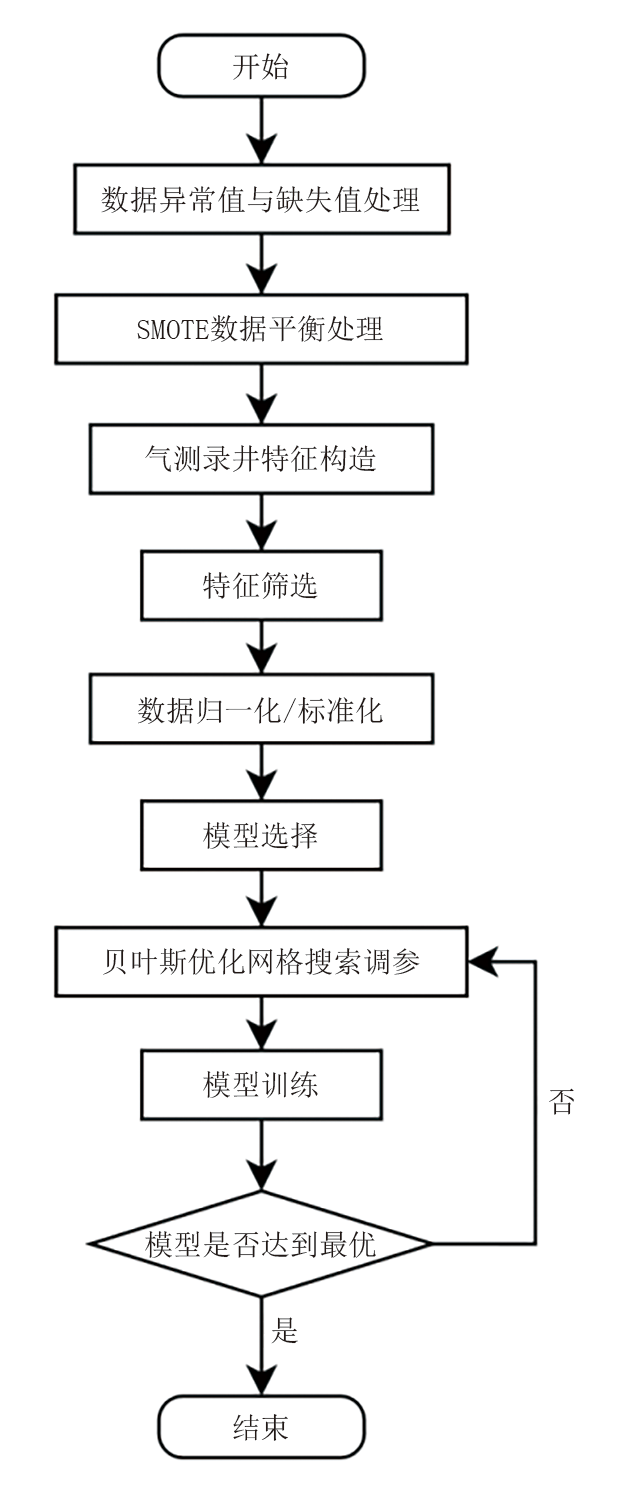 | 图2 气测录井解释机器学习建模流程 |
本文搜集了多口井的气测录井数据, 并将实际的测试结论作为数据标签。原始数据共308条, 参数包括全烃、甲烷、乙烷、丙烷、正丁烷、异丁烷、正戊烷、异戊烷, 测试结论包含油层、气层、凝析气层、差气层4个类别。
依据气测录井解释机器学习建模流程(图2), 首先对原始气测数据进行预处理与特征工程, 然后在数据集上分别使用KNN、NB、SVM、MLP以及LightGBM机器学习模型进行训练, 最后对各个模型的预测效果进行综合对比分析。
2.1.1 异常值与缺失值处理
在数据预处理阶段, 本文采用3
2.1.2 数据平衡处理
原始数据中, 气层、凝析气层、差气层及油层的数据占比分别为51%、24%、15%、10%, 不同类别数据比例极不均衡, 在一定程度上降低了模型性能。为了提高模型性能, 本文应用基于SVM的SMOTE数据过采样方法对数据进行平衡处理。通过算法合成新的少数类(凝析气层、差气层、油层)样本来平衡数据集, 使得模型在训练过程中能够更好地捕捉到少数类的特征和规律, 从而提高模型对少数类的分类能力。
2.1.3 特征构造
传统的气测解释图板通常不直接使用原始气测组分作为图板输入参数, 而是通过对不同参数的组合与运算生成新的参数进行解释, 建立解释图板的过程实际上也是在进行特征工程。因此, 本文构造了气测解释图板中常用的特征参数, 包括湿度比(
式中:C4为nC4与iC4之和, %; C5为nC5与iC5之和, %; Cj为C1-C5之间的各组分;
2.1.4 数据归一化
为了消除不同特征参数量纲对模型的影响, 降低模型计算复杂度并提高模型训练稳定性, 本文使用归一化方法对原始数据进行特征变换, 将原始特征值映射至[0, 1]之间。归一化后的部分实验数据如表2所示, 归一化计算公式如下:
式中:
| 表2 归一化后的部分实验数据 |
本文采用5折交叉验证对模型进行训练, 每次选取20%数据作为测试集, 剩余数据用于模型训练。经过数据平衡处理后的训练样本数为402条, 其中气层、凝析气层、差气层与油层数据占比分别调整为27.6%、27.6%、27.6%、17.2%。为提高结果可靠性, 共进行100次重复训练, 最后对结果取均值。在模型训练过程中, 通过基于贝叶斯优化的网格搜索方法对模型的超参数进行了优化, 具体模型优化参数见表3。KNN模型通过参数n_neighbors控制最近邻的数量, 该参数直接影响模型复杂度、泛化能力和计算效率; NB模型无直接调优参数, 其性能主要依赖于特征选择和数据预处理质量; SVM模型通过参数C平衡模型损失与模型复杂度, gamma作为核函数参数控制决策边界复杂度; MLP模型的hidden_size参数决定了隐藏层的神经元数量, 进而影响神经网络表达能力和训练难度; LightGBM模型中弱学习器数量n_estimators直接影响模型复杂程度, learning_rate为学习率控制模型更新步幅, num_leaves和max_depth用于控制单棵树复杂度。
| 表3 模型优化参数 |
流体性质预测为多分类问题, 为了全面评估模型性能, 本文使用准确率、精准率、召回率作为模型评价指标。在二分类(只包含正样本与负样本)任务中, 常用混淆矩阵来评价模型效果, 混淆矩阵中根据预测类别与实际类别可将预测结果分为TP、FP、TN、FN四类:TP表示实际类别与预测类别一致且均为正类的样本数量; FP表示实际类别为负类, 但被错误预测为正类的样本数量; TN表示实际类别与预测类别一致且均为负类的样本数量; FN表示实际类别为正类, 却被错误预测为负类的样本数量。在气测流体性质预测此种多分类任务中, 可以利用该数据计算模型的预测准确率、精准率、召回率来评价模型对整体以及某个特定类别的分类效果。
2.3.1 准确率
准确率(A)表示所有预测结果中预测正确的样本占总样本的比例, 是衡量分类效果的常用指标, 能够反映模型整体的分类效果。
2.3.2 精准率
精准率(P)表示在所有被模型预测为正样本的结果中, 真实标签也为正样本的比例。精准率侧重于准确度, 尽可能保证预测的结果不出错。
2.3.3 召回率
召回率(R)表示模型正确识别出的正样本在所有正样本中所占的比例, 该指标侧重于全面性, 即尽可能将某一类样本全部识别。
2.4.1 模型预测准确率及分类效果分析
从模型预测准确率(表4)可以看到, SVM模型的效果最好, 平均预测准确率为88.61%, 并且模型预测稳定性也做到了最优; LightGBM模型表现稍弱于SVM模型, 平均预测准确率能达到87.27%; 最简单的NB模型表现最差, 预测准确率在80%以下。此外, MLP模型虽然能达到85%的预测准确率, 但预测结果标准差较大, 表明MLP模型对于不同类别的数据分类能力有较大差别, 稳定性欠佳。
| 表4 模型预测准确率 |
为了评价模型对不同类别数据的分类效果, 本文计算了模型对凝析气层、差气层、气层、油层4类数据的精准率与召回率(表5)。结果显示, 5个模型对于凝析气层和油层都具有较好的识别能力, 虽然油层数据量很少, 但是能够提供足够有效的特征与其他数据区分开。然而, 5个模型对差气层的分类效果都较差。这主要与两方面原因有关:一是差气层整体数据量较少, 数据质量较差, 不能提供足够的信息; 二是在特征工程阶段没有提取出差气层数据的关键特征。对于该问题, 在后续的工作中可以专门针对差气层数据进行处理, 以进一步增强模型的分类能力。
| 表5 模型分类能力 |
2.4.2 数据处理有效性的消融实验验证
消融实验是机器学习中一种验证系统性分析模型各个组成部分对整体性能影响的实验方法, 通过删除模型中的特定模块并观察其对模型造成的性能影响, 从而量化各模块的实际贡献。为了验证数据处理操作的有效性, 本文分别对数据过采样及特征工程进行了消融实验。结果(表6)表明, 在仅使用数据过采样或仅使用特征工程的情况下, 各个模型性能均有不同程度下降:在仅使用数据过采样的情况下, NB、SVM模型性能下降严重, 两个模型对于特征的依赖性较强; 在仅使用特征工程的情况下, 相比其他模型, MLP模型性能受到了较大的影响, 可以证明神经网络不适合小样本的学习。值得注意的是, 在仅使用数据过采样时, KNN模型的准确率不仅没有降低, 反而有小幅度提高, 说明过多的特征对KNN模型中相似度计算造成了干扰。综合实验分析表明, 数据过采样处理与特征工程处理都能够有效提升模型性能。
| 表6 消融实验下各模型性能对比 % |
2.4.3 与图板解释方法效果对比
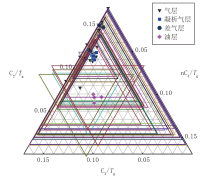
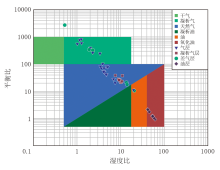
为了进一步验证机器学习模型的解释效果, 本文选取了气测三角解释图板和霍沃斯判别解释图板两种传统方法进行对比分析。气测三角解释图板由三角形坐标系和三角形内价值区组成, 根据三角形内价值区的大小和三角形顶尖的指向判断储层内流体性质; 霍沃斯判别解释图板原理是根据气测组分数据, 计算出湿度比、平衡比和特征比, 然后利用三个比值的大小及其数据组合, 综合判断地层的流体性质。两类图板的解释结果分别如图3、图4所示, 其中气测三角解释图板解释符合率为73.08%, 霍沃斯判别图板解释准确率为67.31%, 均低于本文机器学习模型预测准确率。相较之下, 传统的解释图板存在灵活性不足, 受维度限制难以提取深层信息等问题, 而机器学习模型有效克服了这些问题, 实现了更高的解释准确率。
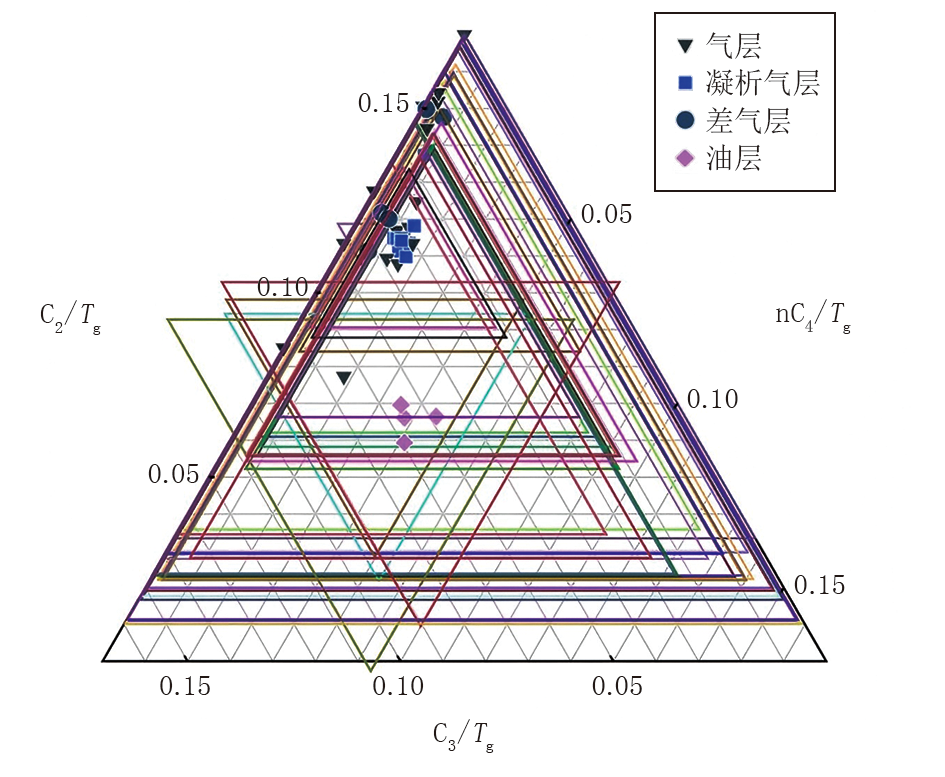 | 图3 气测三角解释图板结果 |
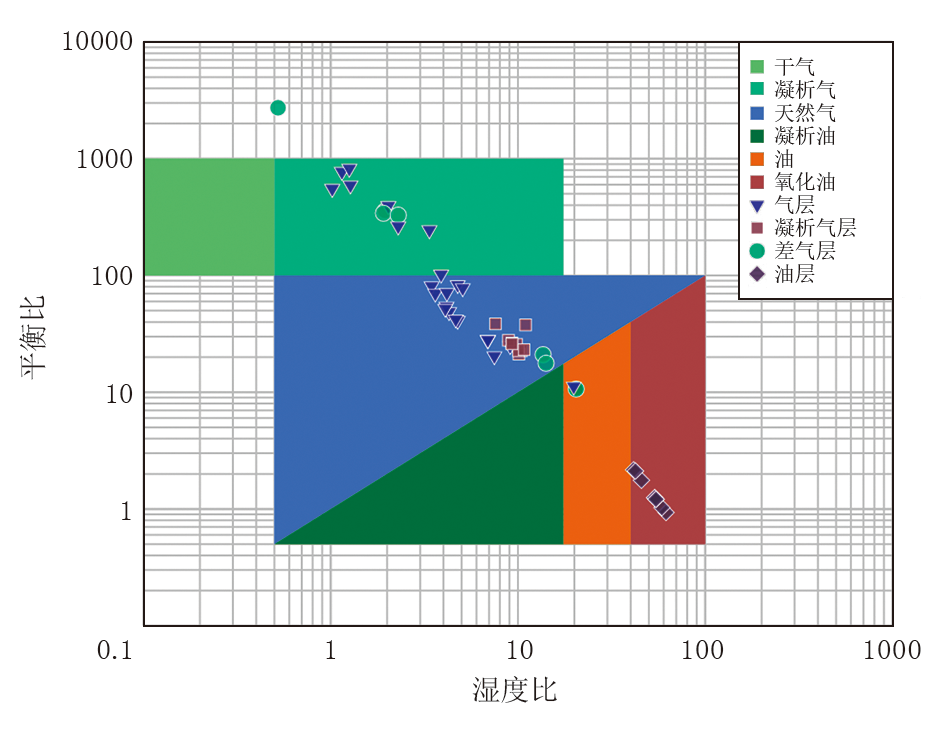 | 图4 霍沃斯判别解释图板结果 |
机器学习技术的发展为解决传统气测解释方法存在的问题提供了新的思路。本文将机器学习算法引入到气测录井解释中, 并根据气测数据以及解释任务本身的特点针对性地设计了建模方法, 完善了面向气测录井解释任务的建模流程。
对比分析了KNN、NB、SVM、MLP、LightGBM等5个常用机器学习模型在真实气测数据集上的建模效果, 结果表明SVM与LightGBM模型综合表现较好, 平均预测准确率达到87%以上, 能够满足实际的解释需要。
在消融实验中验证了数据过采样与特征工程建模流程能够有效提高模型性能, 在后续工作中应该更多关注于提升数据质量以及构造更有效的特征, 以获得更好的模型预测效果。
(编辑 唐艳军)
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|