
{kind=link}
{kind=link}
{kind=link}
钻井数据异构同步系统的研发与应用
[张天啸①, ②  ]
]
]
|
|


作者简介:张天啸 工程师,1989年生,2011年毕业于中国地质大学(武汉)自动化专业,现在中国石油长城钻探录井公司主要从事软件开发工作。通信地址:124010 辽宁省盘锦市兴隆台区石油大街77号录井公司。E-mail:187258869@qq.com
为降低钻井现场数据采集人员的工作量,充分复用已采集到的钻井数据,实现数据“一方录入、多方共享”的效果,通过数据库触发器感知数据变更,凭借模型转换规则动态配置实现数据异构同步,利用消息队列将数据变更捕获与数据同步两个功能解耦提升系统性能,最终研发了钻井数据异构同步系统。该系统自上线以来,累计同步数据2.8亿条,平均每日实时同步数据61.14万条,大幅减轻了现场人员数据填报负担,使得数据共享更加安全和及时,实现了数据同步统一管理。该系统在打破数据壁垒、消除数据孤岛、提高数据利用率、保障数据一致性、促进跨领域协作等方面成效显著,为企业管理者的分析决策活动提供了强有力的数据支撑。
To reduce the workload of data acquisition personnel on the drilling site,fully reuse the collected drilling data,and achieve the effect of "one party entry,multiple parties sharing" of data,data changes are perceived through database triggers,and data heterogeneous synchronization is realized with the dynamic configuration of model transformation rules. The use of message queue to decouple the functions of data change capture and data synchronization improves system performance,ultimately leading to the research and development of a heterogeneous synchronization system for drilling data. Since the system went online,a total of 2.8×108 pieces of data have been synchronized,with an average of 61.14×104 pieces of real-time synchronized data per day,greatly reducing the burden of data filling in and submitting for on-site personnel,making data sharing more secure and timely,and realizing unified management of data synchronization. This system has produced a marked effect in breaking down data barriers,eliminating data silos,improving data utilization rate,ensuring data consistency,and promoting cross-disciplinary collaboration.It provides strong data support for the analysis and decision-making activities of enterprise managers.
随着信息化技术的不断发展, 其在石油勘探领域的应用也越来越广泛, 更多的油田甲方和钻井承包商根据自身需求定制开发了集施工作业数据采集、传输与展示于一体的信息化系统, 为后方专家团队开展远程支持与决策提供帮助。
为满足不同信息化系统对钻井施工数据的采集需求, 钻井工程技术人员需分别对各类信息化系统配套的数据填报软件进行数据录入。这不仅造成数据的重复录入, 还导致工程技术人员花费额外的精力来学习不同软件的操作方法。通过对多支钻井队进行实地考察调研, 发现工程技术人员平均每天要耗费1~2 h来完成此类工作, 部分钻井公司甚至在作业现场设置了信息员岗位, 专门负责数据填报事宜, 增加了企业成本。
为了将工程技术人员从繁重的数据采集和录入工作中解放出来, 钻井公司提出了数据由井场一次性录入后推送给其他信息化系统, 实现施工数据“ 一方录入、多方共享” 的解决方案。目前国内外已有软件公司开发了数据提取和数据迁移工具可用于数据同步, 但是大部分工具存在以下问题:定时同步技术还无法达到良好的同步实时性, 且不支持高级转换规则, 无法应对复杂的异构数据转换, 无法满足钻井数据异构同步的需要。因此, 亟需研发一款运行稳定、数据同步及时、可实现模型自动转换的钻井数据异构同步系统。
构建一套完整的钻井数据异构同步系统需要解决以下3个核心技术问题:①如何定位需要同步的数据; ②如何确定同步的时机; ③如何指定模型的转换规则。
直接将数据源中全部数据进行同步, 需要遍历数据源所有数据表及数据表中的数据行, 数据量越大, 耗费的时间和硬件资源就越多, 这对于具有海量数据的大型信息系统显然是不切实际的。因此, 需要一种机制能够精准定位发生变化的数据(即变更数据捕获Change Data Capture, CDC)[1], 有选择性地进行数据同步, 提高工作效率。目前行业上主流的变更数据捕获方式对比如表1所示[2]。
| 表1 行业主流变更数据捕获方式对比 |
在满足业务需求的前提下, 综合考量系统复杂度、同步实时性和系统独立性等各方面因素, 选择基于触发器来实现数据变更捕获。可根据数据同步业务的需要, 较为灵活地为指定的数据表创建行触发器, 当数据发生新增、更新、删除等变化时, 触发器可自动触发并精准获取到变化的数据[3]。虽然使用触发器会对数据库产生一定的性能损耗, 但在其灵活、简便和可靠的优势面前, 此项缺点几乎可以忽略不计。
数据源中数据的新增、更新和删除等操作是持续进行的, 想要保证数据同步的及时性, 就需要一种机制能够准确感知到数据发生变化的时刻, 以便第一时间启动数据同步任务。基于触发器的变更数据捕获技术, 可在数据变化前BEFORE触发器或变化后AFTER触发器立刻触发感知, 达到实时性要求[4]。随后需要将数据库层面感知到的信息发送给数据转换和推送服务, 这里可利用消息队列的发布订阅机制, 将感知到的信息序列化成Json格式后发布到消息队列, 以便获取数据转化和推送服务订阅指定的主题。
由于各方在系统建设时遵循不同的设计理念和使用需求, 系统底层使用不同的数据存储模型, 数据同步时必然要对数据进行结构转换, 转换规则随双方系统数据模型的差异而变化, 需要运行时动态配置。分析常见的模型转换场景:在数据采样颗粒度不一致时, 需要进行单条数据拆分成多条、多条数据合并成单条的转换; 在单位制和时区存在差异时, 需要进行数据单位转换和时间转换; 在数据模型不一致时, 需要进行数据类型转换和字符串处理。为实现上述转换规则的自由组合, 使用Java编程开发各规则所对应的处理函数, 由用户选择一个或多个函数, 最终形成数据模型转换规则并存储在系统数据库中。执行同步任务时, 系统读取用户保存的规则, 按顺序依次调用函数处理数据以实现模型的自动转换。
系统主要由系统数据库、变更数据捕获服务、消息队列、模型转换服务、数据同步服务5部分组成, 如图1所示。
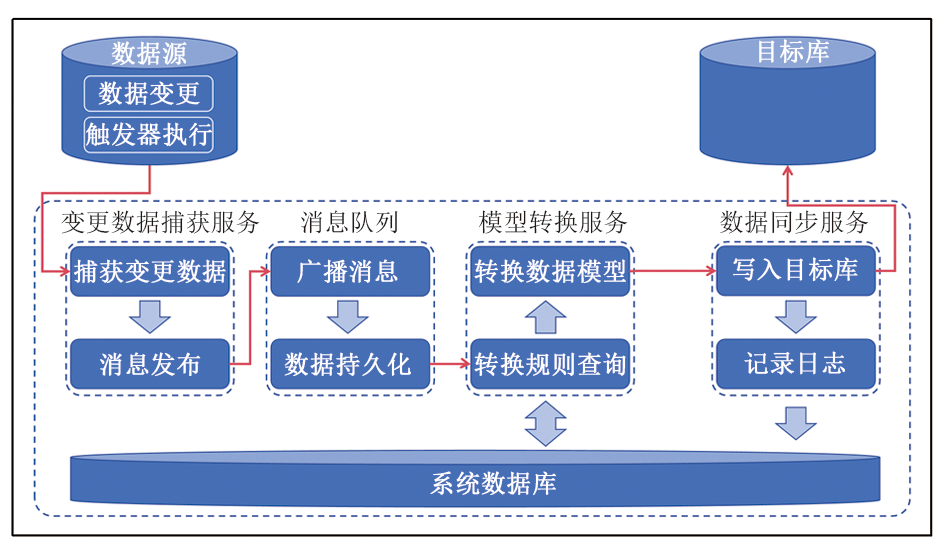 | 图1 系统主要架构及运行流程 |
用来支持系统运行的数据库称为系统数据库, 需在其中预先创建系统运行必备的3个数据表:①同步任务记录表, 主要记录数据同步任务名称、任务描述、数据源连接方式和目标库连接方式, 用于管理同步任务并允许系统连接源数据库和目标数据库; ②数据模型转换规则数据表, 主要记录源数据表名, 源字段名、源字段类型, 目标数据表名、目标字段名、目标字段类型和字段业务含义等内容, 用于向模型转换服务提供用户自定义的数据转换规则; ③数据同步历史记录表, 主要记录执行同步的数据本身、同步执行时间、最后同步结果等内容, 用于数据条目同步历史的在线查询和展示。
变更数据捕获服务是整个系统多个组成部分中最重要的一环, 是整个数据同步流程的发起者。它实质上是使用Java语言在Oracle数据库中编写的数据库函数, 由源数据库在发生新增、更新、删除操作时触发执行。当源数据库中数据发生变化时, 源数据库中的行级触发器获取到变更数据包含主键在内的所有数据列, 通过Oracle数据库内置的 JVM发送给变更数据捕获服务[5], 在Java程序中经过源表名、变更时间、变更类型等必要数据标记后, 序列化成Json格式的通知发布到消息队列。
考虑到源数据库会出现数据高频次、大批量发生变更的情况, 此时如果直接将通知转发给模型转换服务, 可能会触及下游服务在数据处理方面的性能瓶颈而导致任务积压, 进而发生Java运行内存激增、堆栈溢出等异常情况, 严重影响服务运行的稳定性。为了避免上述问题的发生, 需要将变更数据捕获服务对模型转换服务的同步调用改为异步调用, 降低服务之间的强依赖, 增加系统的韧性[6]。因此, 在两服务之间加入消息队列充当消息传递的载体, 变更数据捕获服务产生的消息进入消息队列中排队, 模型转换服务根据实际处理能力, 依序从消息队列中消费消息, 如图2所示。结合消息队列的数据持久化、自动重试和消费确认等机制, 不但能实现服务之间的异步解耦, 还具备流量削峰、可靠通信等优势。
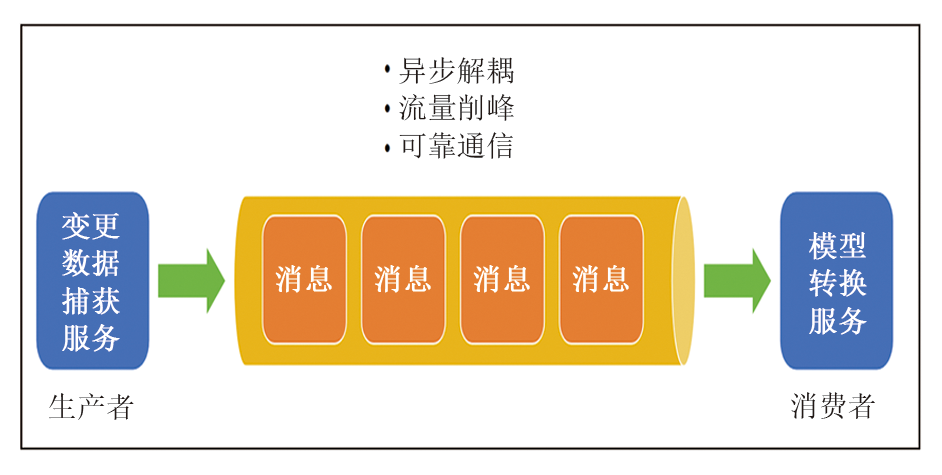 | 图2 消息队列实现服务间异步解耦、流量削峰、可靠通信 |
模型转换服务的主要功能是将变更数据重组成目标库所需要的格式, 方便数据同步服务的后续操作。因此, 该服务需要订阅消息中间件上的指定主题, 实时获取发生变更的数据信息。数据信息主要分为数据结构和数据本体:数据结构标识了数据本体所属的数据表及其拥有的列; 数据本体承载了变更数据所有数据列的值。模型转换服务根据数据结构信息, 在数据模型转换规则数据表中查询本条数据适用的转换规则, 依据规则逐列对数据本体进行类型转换、数值计算、字符串拼接和日期格式转化等操作, 在源数据库和目标数据库存在较大结构差异时, 还需要对源数据进行一对多拆分或多对一合并, 最终形成与目标库结构一致的数据实体。
数据同步服务负责接收模型转换服务转换的数据实体, 将其存入目标库相对应的数据表中。在应用程序与数据库交互的过程中, 性能开销主要存在于网络通信、数据库内核、应用程序3个方面, 为了提高系统运行效率、减少目标库的性能开销, 考虑从这3个方面进行优化设计。
2.5.1 网络通信
应用程序与数据库每次交互都需要占用1个数据连接, 而临时创建新的数据库连接将占用大量的性能开销。因此, 使用数据库连接池来管理数据库连接, 避免数据库连接的大量频繁创建。
2.5.2 数据库内核
每条SQL语句需独立完成“ 查询解析→ 优化→ 执行计划生成→ 资源释放” 流程; 当积攒一定量的数据后进行批量提交时, 数据库内核可自动采取缓存 SQL 模板执行计划、减少索引更新和事务日志等优化措施, 显著提升执行效率[7]。
2.5.3 应用程序
可对同一批次提交数据库修改的数据集进行分析, 把数据库将要进行的操作按先后顺序排成队列, 当队列中出现表2中列出的几种排列情况时, 可对数据提交操作进行优化和精简, 大幅降低数据库实际写入, 提高执行效率。
| 表2 可优化精简的数据提交操作 |
钻井数据异构同步系统整体是一个采用主流前后端分离架构构建的Web系统, 后台使用Java、前台使用Vue语言, 以微服务的形式进行设计。
该系统可适配常见关系型数据库作为系统数据库, 在数据源中为需要进行同步的数据表创建触发器, 统一在触发器中调用存储过程, 再由存储过程调用变更数据捕获服务, 因此需要向数据源注册变更数据捕获服务并创建PL/SQL包装器。消息队列使用RabbitMQ, 并配置好用户、虚拟机和交换机, 以便完成数据的发布和订阅。模型转换服务从系统数据库获取模型转换规则并缓存在Java程序中, 当收到订阅的消息后, 将消息解析成数据源的数据模型对象, 在缓存中查找与其相匹配的转换规则后, 将数据模型对象进行拆解和类型转换, 并重新组装成目标库的数据模型对象。数据同步服务获取到目标库的数据模型对象后, 按主键将对象重新分组, 按组进行数据对象的合并操作后将其写入目标库, 完成数据的同步。
在整个数据同步过程中, 设计全局的异常捕获逻辑, 重点监听与数据同步业务相关的异常信息, 抽取后形成数据同步错误日志供用户随时查询。
基于本设计方案开发的钻井数据异构同步系统自上线至今, 执行数据同步任务1项, 配置模型转换规则14 395条, 涉及530张数据表, 保持466 d稳定运行, 累计同步数据2.8亿条, 平均每日实时同步数据61.14万条, 其中新增操作占比32%, 更新操作占比64%, 删除操作占比4%。上述数据证明该系统各项性能指标均达到设计要求, 完美契合钻探公司对钻井数据异构同步的需要, 应用效果良好。系统运行状态监控页面如图3所示。
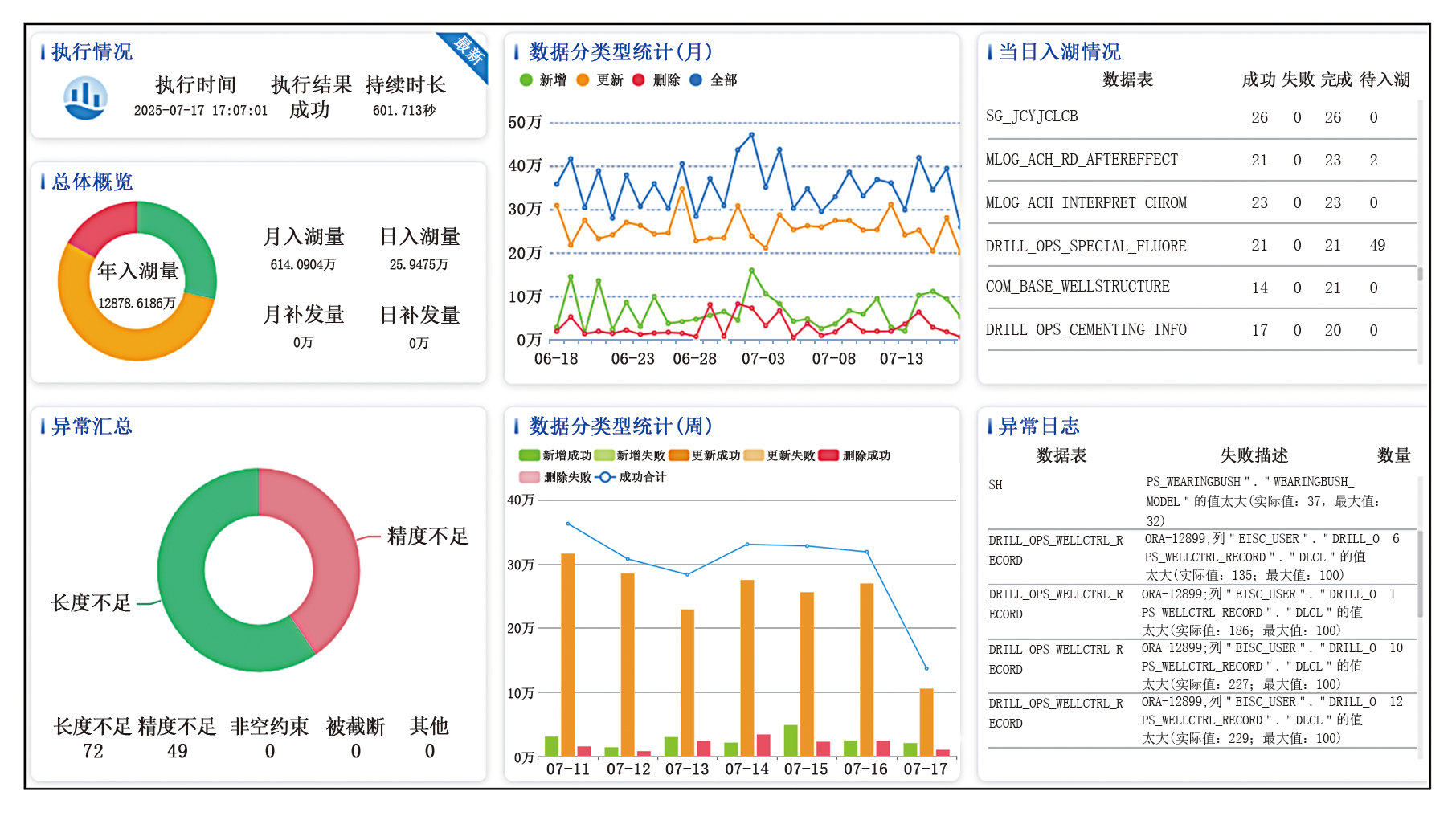 | 图3 系统运行状态监控页面 |
钻井数据异构同步系统的建成与运行, 在3方面产生了积极的作用。
3.2.1 减轻现场人员数据填报负担
彻底终结了施工现场数据重复录入的困境, 所有施工数据仅需在现场录入一次, 便可通过该系统自动同步至其他第三方系统, 真正实现了施工数据的“ 一方录入、多方共享” , 在企业降本增效方面产生了积极的作用。
3.2.2 数据共享更加安全和及时
信息化时代, 任何企业都无法忽视数据安全问题, 在保障数据畅通传递的同时, 需要花费大量的精力和成本防范数据被泄露和窃取。可将企业核心数据库部署在安全的内网环境中, 将钻井数据异构同步系统部署在DMZ区, 合理配置网络安全策略后, 既能实现钻井数据异构同步系统对数据源的正常访问, 又能避免数据源直接暴露在互联网中, 防止黑客攻击, 保证数据安全[8]。
3.2.3 数据同步统一管理
考虑到随着企业业务的增长, 数据的同步需求会不断地发生变化, 会面临更多的目标库、更广泛的数据同步范围、更复杂的模型转换规则。在方案设计时, 将同步任务、模型转换规则做了动态处理, 不需要二次开发即可实现数据同步任务的随时调整。系统为用户提供权限管理功能, 授权指定的用户账号进行任务创建、模型转换规则设置等操作, 非授权用户只能查看任务的执行状态和相关信息, 实现数据灵活配置, 按需授权, 同步精细化管控。
随着信息化技术在石油行业中不断深入应用, 钻井数据作为企业开展工程技术远程支持决策工作的基础, 高效、安全、可靠的钻井数据异构同步技术的应用场景会变得更加广阔。该技术在打破数据壁垒、消除数据孤岛、提高数据利用率、保障数据一致性、促进跨领域协作等方面作用显著, 为管理者的分析决策活动提供了强有力的数据支撑, 是各企业信息化部门在数据治理与应用方面应当储备和深入研究的关键技术。
(编辑 王丙寅)
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|