{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于RF与GA-BP融合模型的深部煤层含气量预测
[王洁①, ②  ]
]
]
|
|


作者简介:王洁 1998年生,西安石油大学地质资源与地质工程专业在读硕士研究生,研究方向为储层测井评价。通信地址:710065 陕西省西安市西安石油大学雁塔校区地球科学与工程学院。E-mail:1462908253@qq.com
精准预测深部煤层含气量,是优选煤层气“甜点区”、部署开发井位和优化压裂方案的关键依据。然而由于传统预测模型在含气量预测中往往存在明显局限,如对复杂非线性关系的表征能力不足、泛化性能较差且易陷入局部最优解,导致预测精度难以满足实际需求。为此在系统分析煤层含气量与测井参数相关性的基础上,优选出声波时差、补偿中子、自然伽马、密度和电阻率5个测井参数作为输入特征,提出了一种融合随机森林(RF)与遗传算法优化BP神经网络(GA-BP)的集成学习模型,首先采用3 σ准则对异常值进行清洗,然后利用随机森林初步完成回归特征重要性评估,进而将其预测结果作为新特征与原始参数融合,输入至经遗传算法优化的BP神经网络进行精细建模。采用5折交叉验证评估模型性能可知,测试集结果为 R²=0.894、 RMSE=1.698、 MAE=1.313。应用井验证结果表明,模型在Y-1、Y-2井含气量的预测绝对误差介于-1.37~1.39 m3/t之间,与实测值吻合良好。该融合模型有效提升了预测精度,表现出良好的鲁棒性和泛化能力,为深部煤层气资源评估提供了可靠技术方法。
Accurate prediction of the gas content in deep coal seams is a key basis for selecting the "sweet spot" of coalbed methane, precisely deploying well sites for development, and optimizing fracturing schemes. However, traditional prediction models often have obvious limitations in gas content prediction, such as insufficient representation ability of complex nonlinear relationships, poor generalization performance, and being prone to falling into local optimal solutions, resulting in prediction accuracy being difficult to meet actual needs. Therefore, based on a systematic analysis of the correlation between coal seam gas content and log parameter, this paper selects five log parameters, namely interval transit time, compensated neutron, natural gamma, density and resistivity as input features, and proposes an ensemble learning model that integrates random forest and genetic algorithm to optimize BP neural networks. This model first uses 3 σ criteria to clean the outliers, uses random forest to initially complete the assessment of the importance of regression features, and then fuses the prediction results as new features with the original parameters and inputs them into the BP neural network optimized by genetic algorithm for fine modeling. The performance of the model is evaluated by using 5-fold cross-validation, the results of the model test set are R² of 0.894, RMSE of 1.698, MAEof 1.313. The verification results of application wells show that the absolute prediction error of this model in wells Y-1 and Y-2 is between -1.37 and 1.39 m3/t, which is in good agreement with the measured values.This fusion model effectively improves the prediction accuracy, demonstrates good robustness and generalization ability, and provides a reliable technical method for the assessment of deep coalbed methane resources.
煤层气作为典型的自生自储型非常规天然气, 其含气量是评价储层特征和预测产能的关键参数。研究含气量的主控因素并实现准确预测, 对于指导煤层气勘探开发与生产部署具有重要意义[1]。传统方法基于绳索取心与等温吸附曲线测定含气量, 虽精度较高, 但成本昂贵、周期较长, 严重制约了其在区域评价和大规模开发中的应用[2]。因此, 利用测井资料构建高效、准确的含气量预测模型, 已成为当前国内外学者研究的重要方向。
近年来, 基于测井数据, 运用机器学习技术预测煤层含气量已成为一个重要研究方向, 旨在挖掘测井响应与含气量之间的复杂非线性关系。Li等[3]在煤层含气量预测研究中, 系统融合测井与地震响应特征, 结合神经网络反演技术, 选取对含气量变化敏感的关键参数, 构建了高精度预测模型, 有效提升了复杂地质条件下煤层含气量的预测准确性。刘晓等[4]基于延川南气田煤层含气量的测井响应特征, 采用平均影响值(MIV)算法定量评估了各测井参数对模型输出结果的贡献度, 并融合BP神经网络与随机森林算法, 构建了一种高精度的煤层含气量预测模型。伍秋姿等[5]综合四川盆地泸州区块龙马溪组页岩储层的岩心实验与测井资料, 系统评估了支持向量回归、梯度提升决策树与极端梯度提升3种机器学习算法的性能, 发现梯度提升决策树(GDBT)模型在该区块深部页岩储层中的预测精度最优, 有效支撑了储层物性精细表征与有利勘探区带优选。刘佳杰等[6]针对储层孔隙结构复杂、矿物组分非均质性强及孔隙度与测井参数间存在显著非线性关系等问题, 提出了一种基于遗传算法优化的一维卷积神经网络(1D CNN)预测模型, 该模型引入去池化层结构来增强特征重构能力, 为复杂储层孔隙度的高精度估算提供了一种高效且适应性广的新途径。
然而, 现有研究方法在深部煤层复杂地质条件下仍面临诸多挑战。深部煤层往往存在更强的非均质性和各向异性, 导致测井响应与含气量之间的关系更加复杂, 多参数耦合效应显著, 常规线性或简单非线性模型难以准确捕捉这种复杂关系。此外, 样本数量有限且不平衡的问题在深部煤层中尤为突出, 给模型训练带来很大困难。针对这些挑战, 本文以X区块深部煤层取心井为研究对象, 基于常规测井资料与实测含气量数据, 通过多特征融合和机器学习算法, 构建一种新型的混合预测模型。该模型融合了随机森林在高维特征筛选中的效能、遗传算法在超参数全局寻优中的优势, 以及神经网络对复杂非线性关系的强大拟合能力, 显著提升了深部煤层含气量预测的准确度, 克服了传统方法精度不足的局限, 对深部煤层气资源的精细评估与有效开发具有实际应用价值。
随机森林(RF)是一种集成学习方法, 其核心原理是通过构建多棵决策树, 并采用投票(分类)或平均(回归)机制集成预测结果[7, 8]。该算法的优势源于其引入双重随机性(样本随机性、特征随机性)来构建强大且稳定模型的设置。
样本随机性:采用Bootstrap技术有放回地从原始训练集中随机抽样, 生成多个训练子集, 每个子集用于训练一棵独立的决策树。在抽样过程中, 约63.2%的样本被抽中用于训练, 其余未被抽中的样本构成“ 袋外数据” , 为模型提供内置验证集[4]。
特征随机性:在决策树的每个节点进行分裂时, 并非从全部特征中挑选最优分裂特征, 而是从M个输入特征中随机选取m个特征(m< M, 通常取m=log2M), 并从中寻找最佳分裂特征。
这种双重随机性机制确保了森林中每棵决策树都具有足够的差异性, 有效降低了模型对特定训练数据和噪声的敏感度, 从而克服了单棵决策树容易过拟合的缺点。最终, 通过“ 集体决策” , 随机森林集成了众多弱学习器的预测优势, 展现出优异的泛化能力和鲁棒性[8]。
BP神经网络凭借其强大的非线性拟合能力得到广泛使用, 但因其依赖梯度下降进行参数优化, 训练过程易陷入局部最优解, 且对初始权重敏感。遗传算法(GA)模拟自然进化机制, 通过“ 选择-交叉-变异” 等操作在高维解空间进行全局优化搜索, 不依赖于目标函数的梯度信息[9]。
本文将GA与BP神经网络相结合, 其中GA负责在全局范围内寻优, 为BP神经网络提供高质量的初始权值与阈值; BP神经网络在此基础上利用梯度下降进行局部精细化调整。这种“ GA全局优化+BP局部收敛” 的混合策略, 利于协同提升模型的全局搜索能力和局部收敛精度。
1.2.1 BP神经网络
BP神经网络是一种多层前馈神经网络, 其核心包括信号的前向传播与误差的反向传播两个过程。在前向传播中, 输入信号经隐含层逐层处理, 最终由输出层生成预测结果; 在反向传播中, 输出层根据预测值与真实值的误差, 基于梯度下降法反向调整各层的权重与偏置参数, 可通过不断迭代使网络输出逼近期望值[10, 11]。
1.2.2 遗传算法
遗传算法(GA)是一种基于“ 适者生存” 原理的全局优化算法[12], 其基本流程如下:首先将优化问题的潜在解编码为“ 染色体” 以构成初始种群; 再在迭代过程中计算每个个体的适应度(如预测误差的倒数), 并依据适应度进行选择操作; 进而对选中的个体执行交叉(信息交换)和变异(引入随机扰动)操作以产生新一代种群。通过如此迭代循环, 直至满足终止条件(如达到最大迭代次数或解质量稳定), 最终输出历史最优解[13]。
为实现深部煤层含气量的高精度预测, 本文提出“ 相关性筛选-异常值清洗-集成建模-系统验证” 的递进式建模框架:首先借助皮尔逊相关系数对深度及测井参数进行定量筛选, 确定模型输入特征集; 随后通过3σ 准则剔除异常样本并进行归一化来统一量纲, 以提升数据质量; 进而构建随机森林(RF)与遗传算法优化BP神经网络(GA-BP)的集成模型, 并采用5折交叉验证对模型性能进行系统评估。
地球物理测井技术以其纵向分辨率高、连续性强且经济高效的优势, 成为预测煤层含气量重要且有效的技术途径。为表征煤层含气量与深度及测井参数之间的内在关联特征, 本文收集了研究区8#深部煤层125块样品的含气量测试数据, 在完成岩性归位处理后, 提取对应层段的常规测井曲线响应数值, 利用皮尔逊相关系数厘清煤层含气量与深度及各常规测井响应参数之间的关联性[14, 15], 其数学表达式为:
式中:r为皮尔逊相关系数; xi、yi分别为第i个样本对应的参数值;
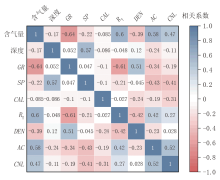
计算结果以相关系数热力图形式呈现(图1)。从图中可以直观地观察到深度、自然电位(SP)及井径(CAL)与含气量的皮尔逊相关系数绝对值均小于0.25, 统计意义不显著而未纳入后续建模; 最终优选出自然伽马(GR)、电阻率(RT)、密度(DEN)、声波时差(AC)及中子(CNL)这5个与含气量显著相关的敏感参数作为预测模型的特征变量。其响应机理可概括为:GR因矿物杂质吸附增强放射性并占据孔隙, 导致吸附能力下降, 故与含气量呈负相关[16]; DEN因吸附气引发基质膨胀, 导致岩石密度降低, 故与含气量呈负相关; AC因含气量增加削弱骨架弹性模量, 导致声速下降与时差增大, 故与含气量呈正相关; CNL则因有机质与束缚水的高含氢量随含气量增加而提升, 故与含气量呈正相关[17]; 而RT受多重变量控制[18], 在本研究区与含气量呈正相关。
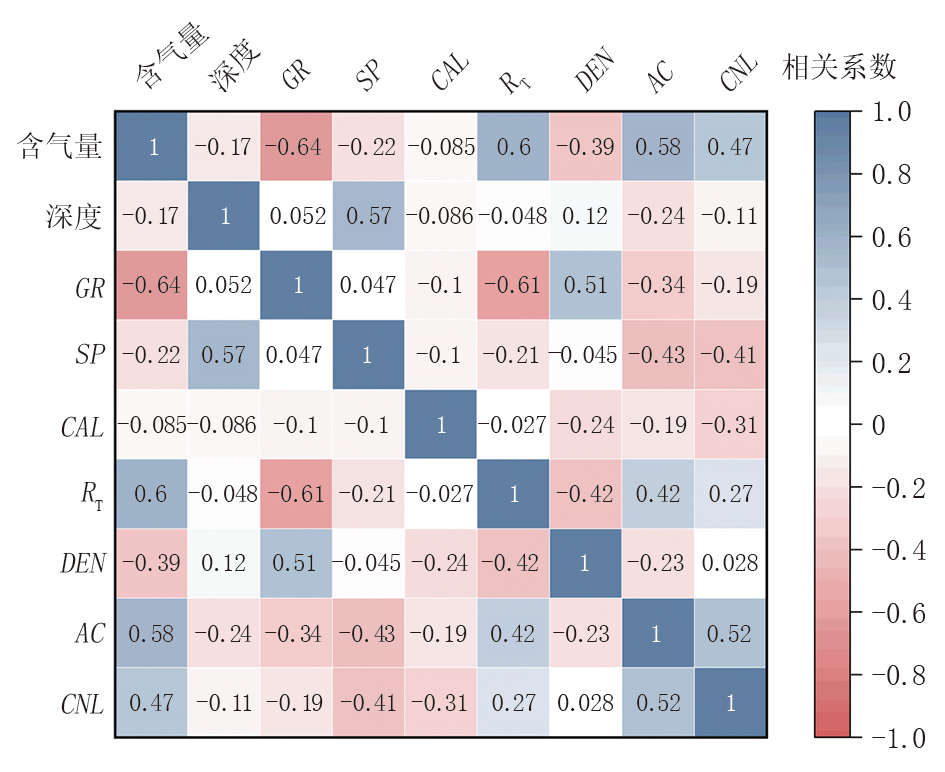 | 图1 含气量与深度及常规测井参数相关系数热力图 |
在利用测井数据构建预测模型的过程中, 原始数据可能因仪器测量误差、井下复杂环境或数据记录疏漏而包含异常值。这些异常数据点通常偏离主体数据分布, 若直接用于模型训练, 会干扰模型学习数据内在规律, 进而造成模型预测准确性降低与泛化性能下降。因此, 本研究采用3σ 准则(又称拉依达准则)对数据进行异常值清洗[19]。
该准则基于正态分布假设, 对每个特征变量计算其均值μ 和标准差σ , 将超出μ ± 3σ 范围的数据视为异常值予以剔除。具体步骤包括:①初始化异常标识矩阵; ②对每个特征列单独计算均值和标准差; ③标记超出μ ± 3σ 范围的数据点; ④删除被标记为异常的数据行。
经过异常值清洗后, 原始数据中的125个样本保留124个有效样本。该方法显著改善了数据集质量, 为后续模型训练提供了更可靠的数据基础, 有助于提升模型的预测精度与泛化能力, 是构建高性能预测模型的重要环节。
机器学习模型的表现受输入数据质量及其分布特征的影响。在深部煤层含气量预测过程中, 所使用的测井特征不仅物理意义不同, 其量纲和数值范围也存在巨大差异。例如, 电阻率的数值范围可达数千Ω · m, 而密度的数值仅在1.3 g/cm³ 左右波动。这种数量级上的差异若不经处理直接输入模型, 会导致模型收敛速度慢和模型偏好失真等问题, 为解决这些问题, 必须对数据进行归一化处理, 即采用最大最小归一化方法将所有特征转换到同一尺度上, 其计算公式如下[20]:
式中:Y′ 为样本归一化后的数值; Y为原始数据集的实测值; Ymin、Ymax分别为原始数据集的最小值和最大值。
2.4.1 随机森林初步预测与特征构建
本研究利用MATLAB的TreeBagger函数构建包含200棵决策树的随机森林模型。采用回归方法, 并开启袋外误差(OOB)计算, 以便评估特征的重要性。将随机种子固定为2008, 以保证实验过程与结果具备可复现性。随机森林以其强大的特征处理能力和抗过拟合特性, 对原始测井特征进行初步学习和预测, 最终输出两个关键结果。
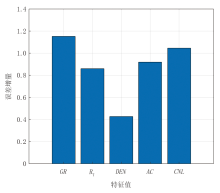
一是特征重要性评估。通过量化并评估各输入特征对于预测目标的重要性, 为模型提供可解释性。基于随机森林的袋外误差可评估特征重要性, 其核心机制为:对某一特征的值进行随机置换, 并计算由此导致的模型预测误差平均上升幅度, 误差增量越大, 说明模型越依赖该特征做出正确预测。从图2中可以看出, GR和CNL对含气量预测的贡献最大, RT和AC次之, DEN相对较低。
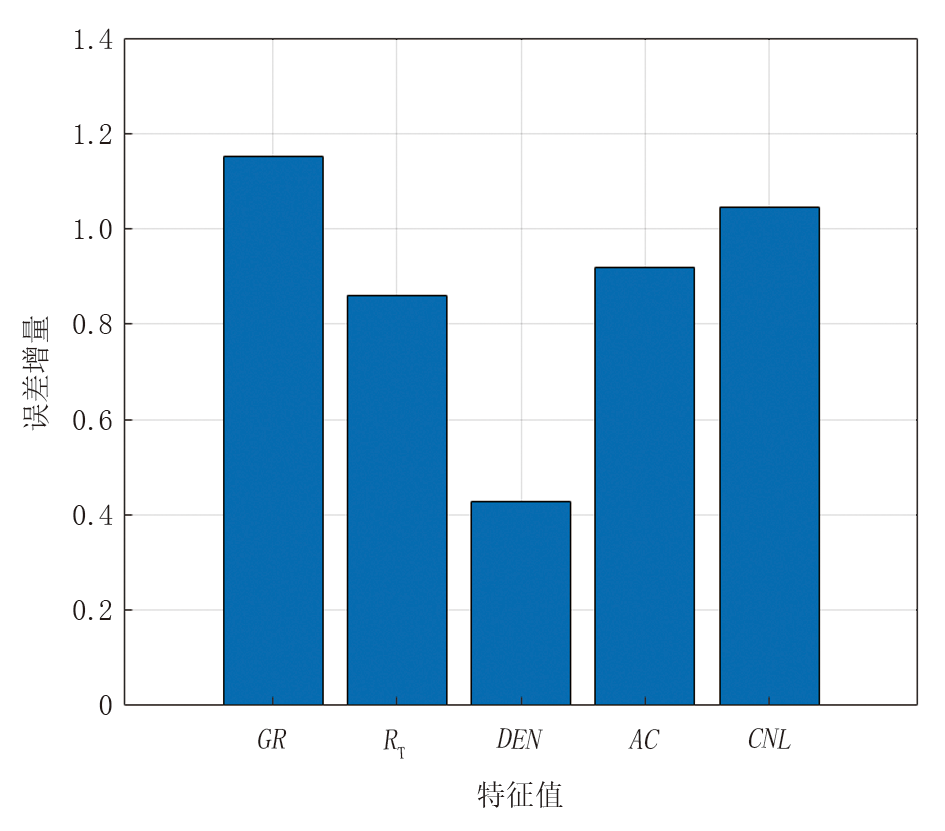 | 图2 随机森林特征重要性排序 |
二是特征增强策略。为杜绝数据泄露, 确保GA-BP模块评估的公正性, 随机森林预测特征的生成过程被嵌入在一个5折交叉验证框架内[21]。构建增强特征集具体步骤包括:①将全部数据集随机、均匀地划分为5个互不重叠的子样本集; ②依次进行5轮训练与预测, 在每一轮使用其中4折作为训练集来训练一个独立的随机森林模型, 并用该模型对剩余的1折验证集进行预测, 得到该折数据对应的随机森林预测值; ③遍历所有子样本集后, 每个样本都获得了由一个“ 未见过该样本” 的模型所生成的预测值, 最后将所有样本的随机森林预测值组合成特征向量, 与原始测井参数进行拼接, 构成用于第二层模型输入的6维增强特征矩阵X2。
X2=[AC, CNL, GR, DEN, RT,
式中:X2为增强后的6维特征矩阵;
这一步骤有效地融合了RF模块强大的非线性拟合能力, 为GA-BP模块提供了更丰富、更具判别性的信息, 且确保了后续GA-BP模块在训练和验证过程中所使用的
2.4.2 遗传算法优化BP神经网络
以融合后的特征矩阵X2为输入, 构建BP神经网络模型, 实现含气量的最终预测。为解决BP神经网络的局部收敛问题, 采用遗传算法优化其权重参数。
(1)网络结构设计:输入层节点数为6(原始特征AC、CNL、GR、DEN、RT与预测值
式中:f1(x)为隐含层神经元的最终激活输出, 介于0和1之间; x为输入特征的加权和。
输出层采用线性函数以避免预测值范围受限, 训练算法采用贝叶斯正则化, 该算法能够在训练过程中自动调节正则化参数, 有效提高模型的泛化能力, 防止过拟合。
(2)遗传算法参数设置:种群大小为30, 最大迭代次数为60, 最大验证失败次数为8, 交叉概率0.8, 变异概率0.1。其中适应度函数通过均方误差(MSE)转换为适应度值, 将最小化MSE的问题转化为最大化适应度值F的问题, 从而有效指导遗传算法搜索最优的权重组合, 计算公式如下:
式中:F为个体的适应度值; MSE为均方误差;
(3)模型训练与预测:将GA算法优化后的权重赋予BP神经网络, 使用训练集进行微调, 然后对测试集进行预测, 输出最终含气量预测值
式中:X2=[AC, CNL, GR, DEN, RT,
本文采用5折交叉验证方法评估模型的泛化性能。具体而言, 在获得由2.4.1节生成的增强特征集后, 再进行一次5折交叉验证以便训练和评估最终的GA-BP模型。对模型性能采用决定系数(R² )、平均绝对误差(MAE)与均方根误差(RMSE)进行量化验证[22, 23], 计算公式如下:
式中:
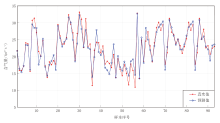
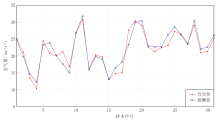
在训练集上, R2=0.911, RMSE=1.619, MAE=1.270; 在测试集上, R2=0.894, RMSE=1.698, MAE=1.313。这一结果在煤层含气量预测领域属于较高精度水平。如图3和图4所示, 该模型在训练集与测试集上均表现出良好的预测性能。训练集的预测值与真实值的变化趋势高度一致, 大部分样本的预测误差控制在较小范围内, 特别是含气量在15~30 m³ /t的中等区间预测精度最高; 测试集的预测精度虽然略低于训练集, 但整体上仍保持了较好的预测能力, 在极端值区域(如含气量< 15 m³ /t), 预测误差相对较大, 这与训练样本在这些区间的数量较少有关。
 | 图3 训练集含气量预测结果对比 |
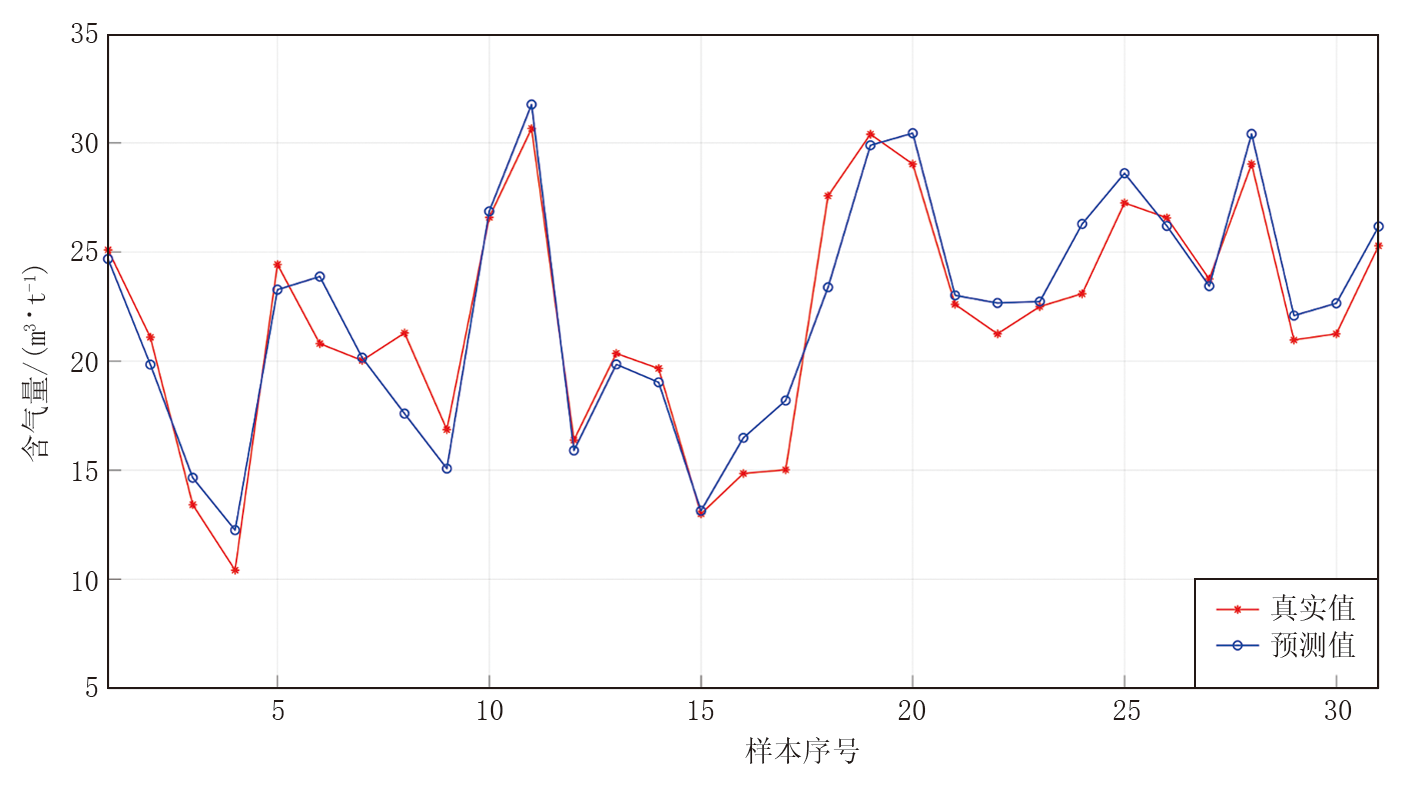 | 图4 测试集含气量预测结果对比 |
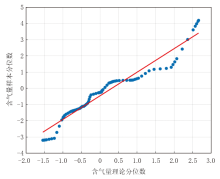
Q-Q测试误差图(图5)显示, 大部分数据点紧密地分布在中央的对角参考线周围, 尤其是中间部分(介于-1到1个标准差之间)。两端的点虽有轻微偏离, 但整体趋势与对角线高度重合, 未出现系统性的弯曲, 误差分布接近正态, 表明模型的预测误差是随机的、无偏的, 不存在系统性的高估或低估缺陷。
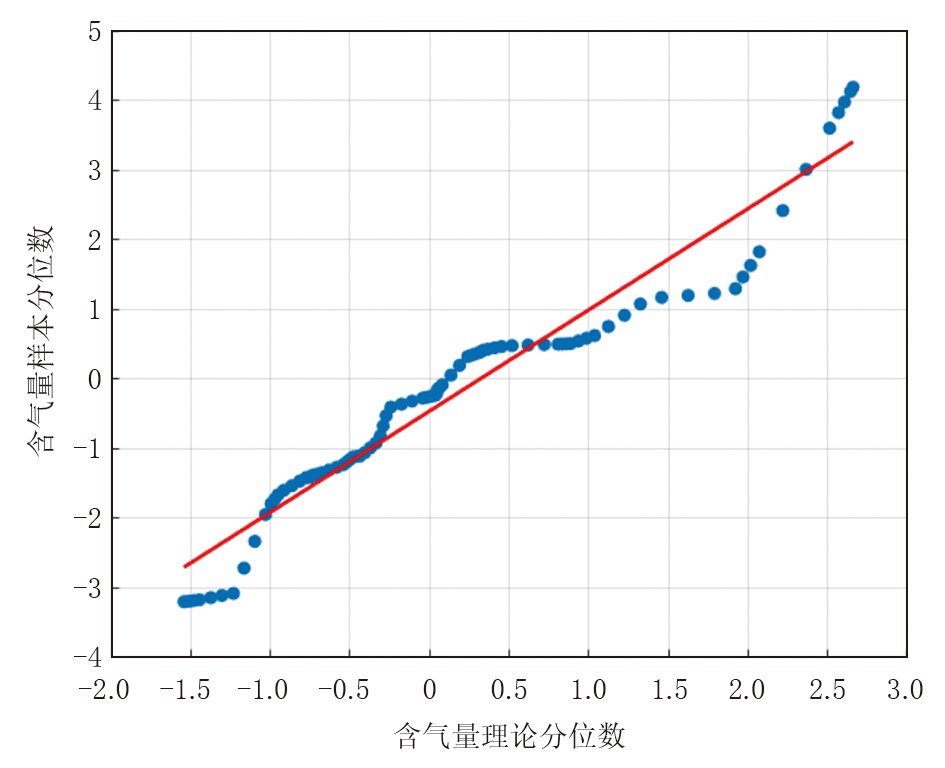 | 图5 Q-Q测试误差图 |
通过对预测结果的深入分析, 发现误差主要来源于以下3个方面:①数据质量限制, 尽管进行了异常值处理, 但测井数据本身存在测量误差和环境影响, 这些噪声难以完全消除; ②特征表达能力有限, 现有的5个测井参数虽然与含气量相关, 但可能无法完全表征煤层的复杂特性; ③模型局限性, 即使采用了集成学习策略, 模型对极端情况的处理能力仍有提升空间。因此, 未来工作将重点围绕数据质量提升、特征工程优化以及模型结构改进等方面展开, 以期进一步提高含气量预测精度与泛化能力。
为验证本文所构建的RF与GA-BP融合模型在实际生产中的泛化能力与预测精度, 将完全未参与模型训练与测试的取心井Y-1、Y-2井作为盲井, 应用该模型对8#煤层含气量进行预测(表1)。
| 表1 8#煤层含气量实测值与预测值对比 |
由表1可知, 模型在Y-1井与Y-2井共8个样本上的预测值与实测值吻合良好。Y-1井煤层埋深在2 300 m左右, 实测含气量平均值为26.78 m3/t; Y-2井煤层埋深在2 010 m左右, 实测含气量平均值为26.59 m3/t。8个样本模型预测煤层含气量绝对误差为-1.37~1.39 m3/t, 平均绝对误差为0.74 m3/t, 误差范围完全满足煤层气勘探工程的精度要求。
基于盲井数据的验证结果表明, 本文构建的RF与GA-BP融合模型在面对未知样本时, 依然能保持极高的预测稳定性与准确性, 不仅验证了该模型具备优异的泛化能力, 也体现了其在现场应用中具有较高的可靠性, 展现出良好的适用性与实用效果。
本研究提出了一种融合RF与GA-BP的混合机器学习模型, 用于进行深部煤层含气量的高精度预测。通过引入RF的预测结果作为增强特征, 并结合GA对BP神经网络初始权重与超参数的全局优化, 显著提升了模型的表达能力和收敛特性。预测结果表明, 该模型在测试集上表现出优异的预测性能(R² =0.894, RMSE=1.698, MAE=1.313), 且训练集与测试集性能差异微小, 表明模型具有卓越的泛化能力和稳定性。误差分析显示, 模型预测误差基本符合正态分布, 95.4%的样本预测误差控制在± 1.5 m3 /t范围内, 完全满足煤层气勘探工程的精度要求。特征重要性分析进一步表明, 研究区自然伽马与补偿中子为最具影响力的特征参数, 与煤储层地球物理响应机理高度一致, 增强了模型的可解释性与地质应用价值。
本研究建立的“ 相关性筛选-异常值清洗-集成建模-系统验证” 系统化方案, 为深部煤层含气量的精确预测提供了有效方法支持, 并对提升煤层气储层评价的准确性与可靠性具有实际应用价值。
(编辑 卜丽媛)
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|