



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
页岩岩相随钻录井识别模型研究与应用
[解清斌①  , 田立强
, 田立强① , 袁胜斌① , 韩学彪① , 陈沛② ]
, 田立强|
|


作者简介:解清斌 工程师,1988年生,2013年毕业于中国石油大学(华东)石油工程专业,现在中法渤海地质服务有限公司从事录井资料解释工作。通信地址:300457 天津市开发区信环西路19号天河科技园1号楼3层。E-mail:xieqb@cfbgc.com
随着页岩油气勘探开发的深入,岩相识别成为页岩油储层评价与甜点预测的关键环节。针对传统岩相识别方法(如岩心观察、测井解释)成本高、连续性差等问题,通过X射线衍射(XRD)及有机地球化学测试等录井资料,结合“有机质丰度+沉积构造+无机矿物含量”的“三端元-三级次”岩相划分方法,将南海涠西南凹陷页岩划分为10种岩相类型,在汇编矿物、岩石热解和工程3类录井数据特征指标的基础上,选取黏土矿物、长英质矿物、碳酸盐矿物、总有机碳含量、氢指数、含油饱和度、钻速、扭矩、热解烃、游离烃共10种特征指标,分别采用支持向量机(SVM)和随机森林(RF)算法,构建页岩岩相识别模型。结果表明:随机森林模型能够准确识别页岩岩相,其准确率为92%;模型在现场应用效果良好,符合率达到100%。该研究成果能够随钻快速地实现岩相识别,为页岩储层的甜点评价及压裂分段分簇设计提供指导。
With the deepening of shale oil and gas exploration and development,lithofacies identification has become a key link in shale oil reservoir evaluation and sweet spot prediction. Aiming at the problems of high cost and poor continuity of traditional lithofacies identification methods (such as core observation and well logging interpretation),this paper divides the shale in Weixinan Sag,South China Sea into 10 lithofacies types through X-ray diffraction (XRD) and organic geochemical logging data,combend member three-end meber-third-order lithofacies classification method of "organic matter abundance+sedimentary structure+inorganic mineral content". On the basis of compiling three types of mud logging data characteristic indicators:mineral,rock pyrolysis and engineering,this paper selects 10 characteristic indicators including clay minerals,felsic minerals,carbonate minerals, TOC, HI, oil saturation, ROP, torque, S2, S1 to construct a shale lithofacies identification model using support vector machine (SVM) and random forest (RF) algorithms respectively. The results show that the random forest model can accurately identify shale lithofacies,and its accuracy rate is 92%. The model has a good application effect in the field,and the coincidence rate reaches 100%. The results of this study can quickly realize lithofacies identification while drilling,and provide guidance for sweet spot evaluation and fracturing stage and cluster design of shale reservoirs.
中国作为页岩油气储量资源丰富的国家[1, 2, 3], 在渤海湾盆地济阳坳陷[4, 5]、南襄盆地泌阳凹陷、松辽盆地[6, 7]、三塘湖盆地[8, 9]及北部湾盆地[10, 11]等多个地区均已获得页岩油流。目前页岩油的研究主要集中在有机-无机化学特征、储层定量表征、赋存机理等方面[12, 13, 14], 现有方法多聚焦于单个页岩样品分析, 难以高效且精准地识别全区有利层位及页岩油空间分布。由于页岩岩相能够反映沉积成岩的有机组合单元, 代表相近或相邻关系的岩石类型[15], 为解决上述难题提供了有效途径, 对页岩油有利层段划分和平面甜点区域圈定具有重要意义[16]。
页岩岩相划分需综合考量含油性与可压性的影响, 通常将有机质丰度、岩石构造特征及矿物组成作为核心分类依据[17, 18]。尽管岩心观察和薄片分析可获取岩相信息, 但全井段连续取心成本高昂, 难以实现全覆盖; 此外, 测井曲线存在信息冗余、数据集类间分布不均等问题, 导致线性方程与经验统计公式难以精准刻画页岩岩相特征。因此, 许多专家学者提出采用机器学习算法解决上述问题, 这种方法不仅能降低岩相解释成本, 且能进一步提升分析的精确度。如:Bhattacharya等[19]采用支持向量机来识别巴肯页岩岩相, 结果显示其准确度高于人工神经网络和多分辨率聚类算法; Al-Mudhafar等[20]基于K-means聚类算法, 结合自然伽马、核磁共振、声波时差等11种测井资料, 实现了对伊拉克南部西库尔纳油田5种碳酸盐岩岩相的识别。
本文借助岩心观察、岩屑录井数据解析等方法, 结合X射线衍射(XRD)矿物分析与有机地化测试等资料, 对南海涠西南凹陷页岩油储层开展了岩相划分研究。通过支持向量机(SVM)、随机森林(RF)2种机器学习算法分别构建页岩岩相识别模型并优选出适用于研究区块的准确识别模型, 进而建立岩相的快速识别方法, 通过识别高有机碳含量、高脆性矿物的优势岩相, 可快速定位储集性与含油性俱佳的核心甜点层段, 指导差异化压裂参数设计, 从而为储层高效改造提供关键地质依据。
岩相是指岩石或沉积物在形成过程中, 受沉积环境、物质组成、结构构造及成岩作用等因素共同影响而形成的综合特征组合。岩相研究主要以岩石物质组成、结构构造为切入点, 通过分析矿物成分、粒度分选、层理特征等, 反演沉积环境与成岩过程, 揭示垂向沉积旋回与平面地理格局[21, 22]。
作为兼具生烃与储集功能的页岩, 其矿物构成、沉积构造蕴含了丰富的成因演化信息。在沉积岩综合评价中, 有机质丰度是沉积岩品质的关键参数之一。因此, 在进行页岩岩相划分时, 需要综合考虑地质要素, 在分类方案中注重实用性和可操作性, 以确保能够有效指导油气勘探实践[22]。通过分析大量录井资料, 在前人划分方案的基础上, 本文采用“ 三端元-三级次” 的划分方法, 针对涠西南凹陷研究区, 建立了以有机质丰度、沉积构造及无机矿物含量为核心的页岩岩相分类体系。
1.1.1 有机质特征
在页岩油气资源评价体系中, 有机质的组分类型、丰度、成熟度及母质类型等是衡量烃源岩质量的核心指标[23]。有机质丰度是控制页岩油气富集与高产的关键因素。为明确研究区烃源岩特征, 对A-1、A-4井开展岩石热解实验, 结果如图1所示。A-1井总有机碳含量(TOC)为0.40%~8.03%(均值3.68%), 游离烃S1含量为1.35~22.62 mg/g(均值9.80 mg/g), 热解烃S2含量为3.05~61.10 mg/g(均值33.68 mg/g), A-4井TOC为0.07%~2.67%(均值1.65%), 游离烃S1含量为0.11~6.80 mg/g(均值3.93 mg/g), 热解烃S2含量为3.15~28.24 mg/g(均值16.60 mg/g)。表明该区域泥页岩具备较高的可动油含量与良好的生油潜力。
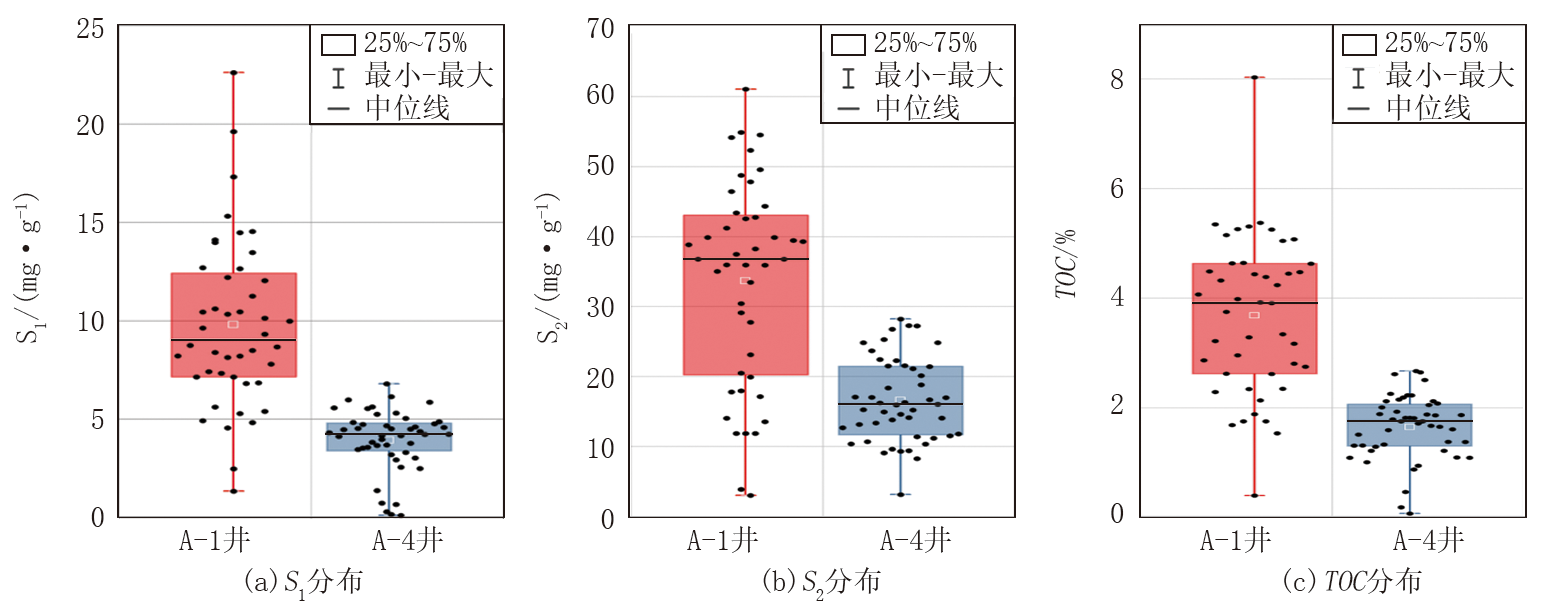 | 图1 岩石热解特征图 |
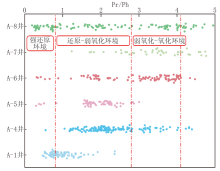
梅博文等[24]研究表明, 沉积环境对烃源岩和原油的Pr/Ph(姥鲛烷/植烷)比值具有显著影响。盐湖和咸水湖相沉积体系通常显示植烷优势, 其Pr/Ph比值普遍小于0.8, 呈现强还原环境; 淡水-半咸水湖相沉积的Pr/Ph比值多分布在0.8~2.8之间, 反映还原-弱氧化环境; 而淡水湖相沉积的Pr/Ph比值通常高于2.8, 最高可达4.0以上, 表征弱氧化-氧化环境。研究区油页岩Pr/Ph比值多介于0.8~4.1之间, 主要分布于淡水-半咸水湖相范围, 以偏淡水和淡水-微咸水环境为主(图2)。
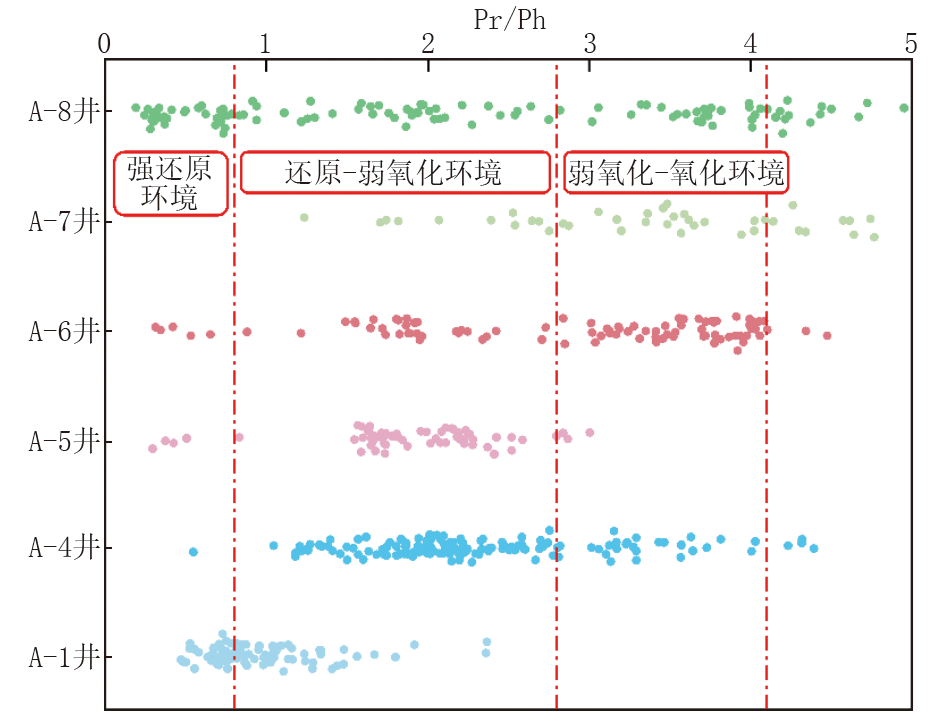 | 图2 研究区Pr/Ph比值分布特征图 |
根据研究区所处偏淡水和淡水-微咸水环境, 同时结合Q/SY 02035-2022《页岩油录井技术规范》, 故研究区采用淡水湖盆的有机质分类标准进行分类:富有机质为TOC≥ 4.0%, 含有机质为2.0%≤ TOC< 4.0%, 贫有机质为TOC< 2.0%。
1.1.2 沉积构造
基于测录井数据, 综合岩石类型、岩性组合特征、基质孔隙与微裂缝的发育状况, 将页岩油储层划分为3类:基质型、纹层型和夹层型[25, 26]。
基质型页岩油储层主要发育富有机质的纹层状、层状泥质灰岩和灰质泥岩, 局部可见厚度小于1 cm的砂岩、灰岩及白云岩薄夹层。该类储层以发育基质孔隙系统为特征, 油气主要储存在基质孔隙网络、微裂缝、有机质孔隙中, 此外, 部分烃类以吸附态赋存于有机质和矿物颗粒表面。
纹层型页岩油储层岩性为浅灰色粉-细砂岩、粉砂岩与深灰色烃源岩交互分布。砂层主体单层厚3~8 cm, 最厚23 cm, 发育平行层理、沙纹层理、粒序层理, 砂岩与下层页岩呈弱冲刷接触且靠近断层, 构造缝发育, 裂缝预测难度大。
夹层型页岩油储层岩性主要为含有机质的泥岩、砂岩、泥质砂岩、灰质砂岩、灰岩、白云岩、云灰岩、泥灰岩、砂质灰岩, 单层厚度10~20 cm, 其中, 泥质砂岩常发育生物扰动构造、波状层理, 泥岩则主要发育水平层理。
1.1.3 无机矿物含量
对研究区页岩样品开展了XRD分析。如图3所示, 工区细粒沉积岩的矿物组成主要包含石英、钾长石、斜长石、方解石、铁白云石、菱铁矿、黏土矿物、黄铁矿等。通过分析可得, 石英含量高达29%~75%, 其平均含量为40.8%; 黏土矿物次之, 含量为20%~51%, 平均含量为37.3%; 其他矿物的平均含量均小于10%。
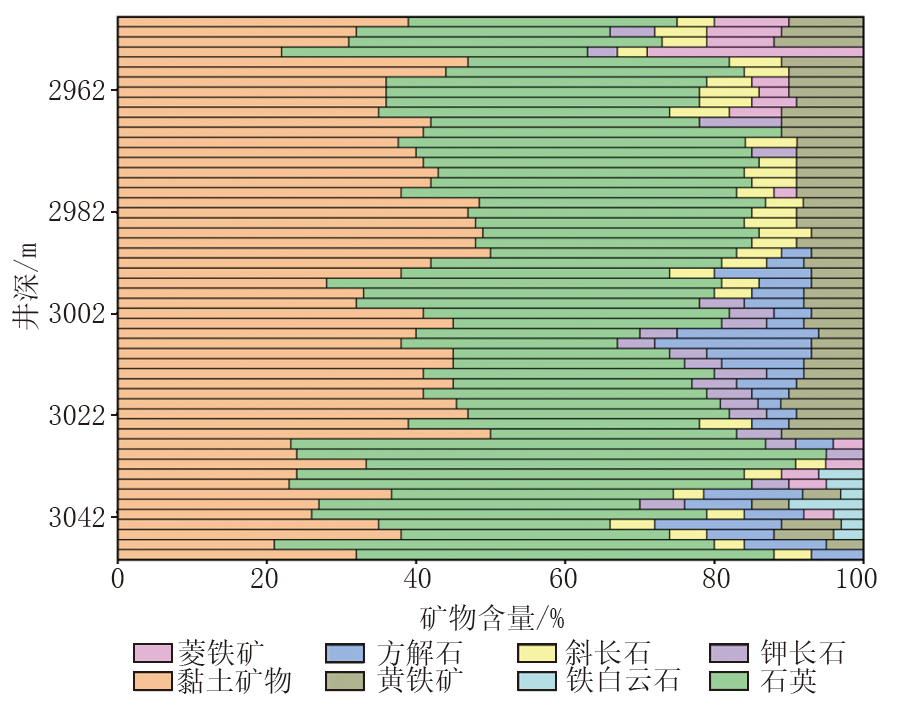 | 图3 XRD矿物组分分析 |
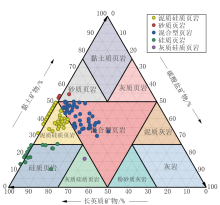
利用矿物组分分类三角图对测试样品进行类型划分。如图4所示, 将所有样品的数据点投在矿物组分分类三角图上, 以确定不同矿物的分类特征。根据长英质矿物、黏土矿物和碳酸盐矿物的相对含量, 将研究区页岩岩相划分为4类:硅质页岩、泥质硅质页岩、混合型页岩、砂质页岩。
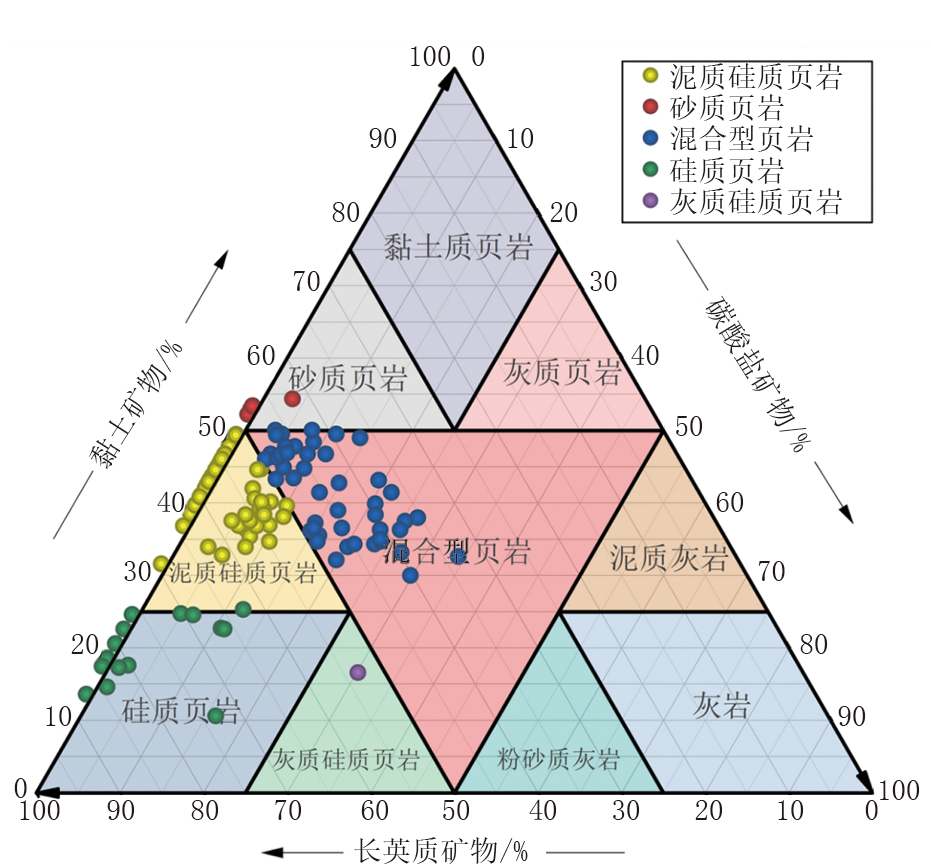 | 图4 矿物组分分类三角图 |
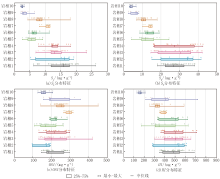
统计不同岩相的游离烃(S1)、热解烃(S2)、含油饱和度(OSI)等岩石热解录井数据, 开展不同岩相下岩石热解特征差异性分析, 如图5所示。分析结果表明:基质型岩相(序号1、2、5)和纹层型岩相(序号3、4、7、10)的S1(均值8.57 mg/g)、S2(均值30.71 mg/g)较高, 其油气显示和生烃潜量较好, 夹层型岩相(序号6、8、9)则相对较低; 夹层型岩相的OSI(均值289.78 mg/g)相对较高, 其页岩油的流动性相对较好, 纹层型岩相次之, 基质型岩相页岩油流动性适中; 氢指数(HI)分析显示, 基质型岩相页岩HI值普遍高于500 mg/g, 表明其以Ⅰ 型干酪根为主, 具备更强的液态烃生成潜力, 而夹层型岩相HI值较低(约400 mg/g), 反映其有机质类型向Ⅱ 型过渡。
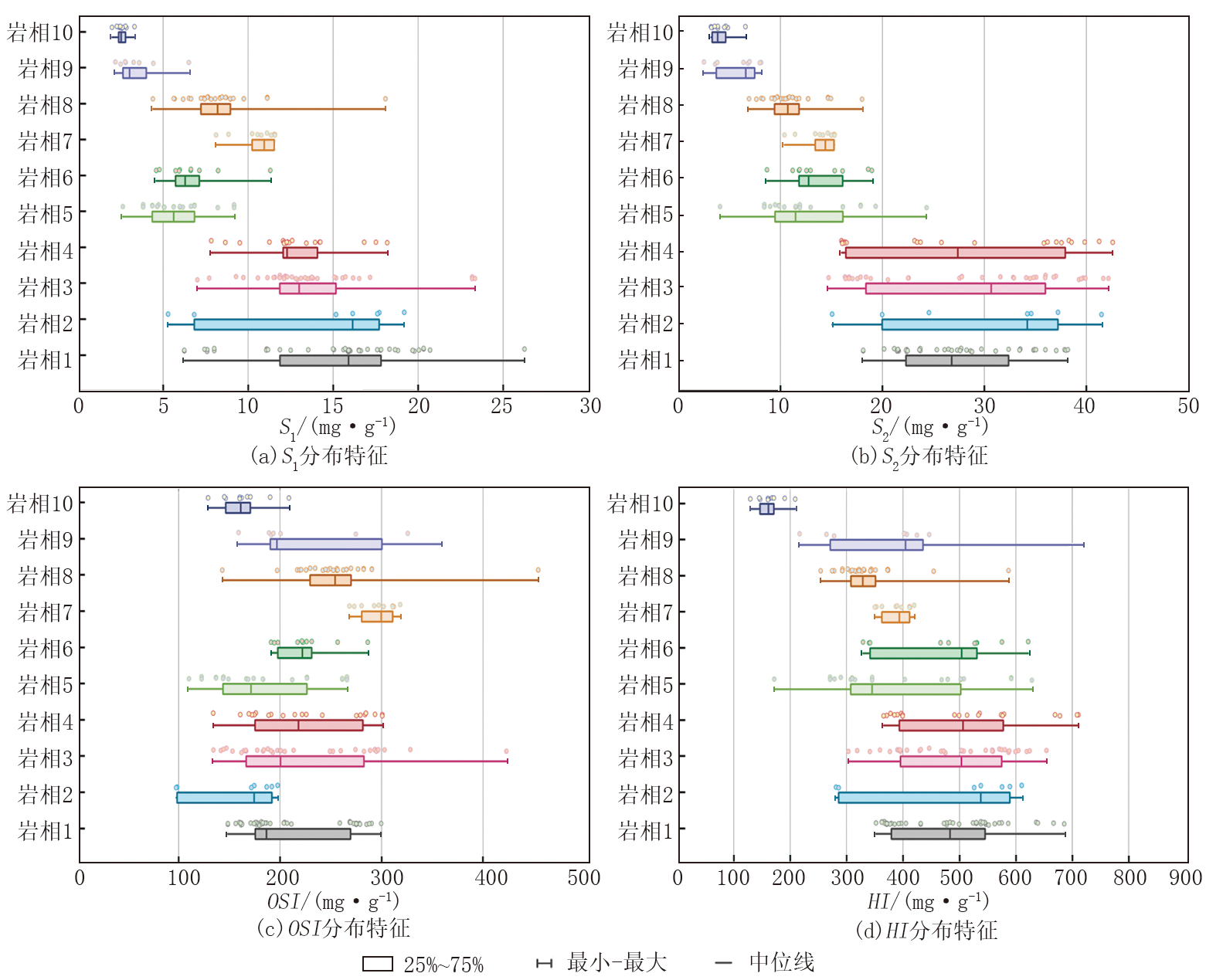 | 图5 不同岩相岩石热解参数特征 |
通过分析不同岩相的钻井参数(如扭矩(TRQ)和钻速(ROP)), 如图6所示可以得出基质型岩相平均钻速13.22 m/h, 平均扭矩值为14.98 kN· m, 岩石可钻性相对较低; 纹层型岩相平均钻速13.38 m/h, 平均扭矩值为13.79 kN· m, 可钻性适中; 夹层型岩相平均钻速14.04 m/h, 平均扭矩值为12.86 kN· m, 岩石可钻性强。
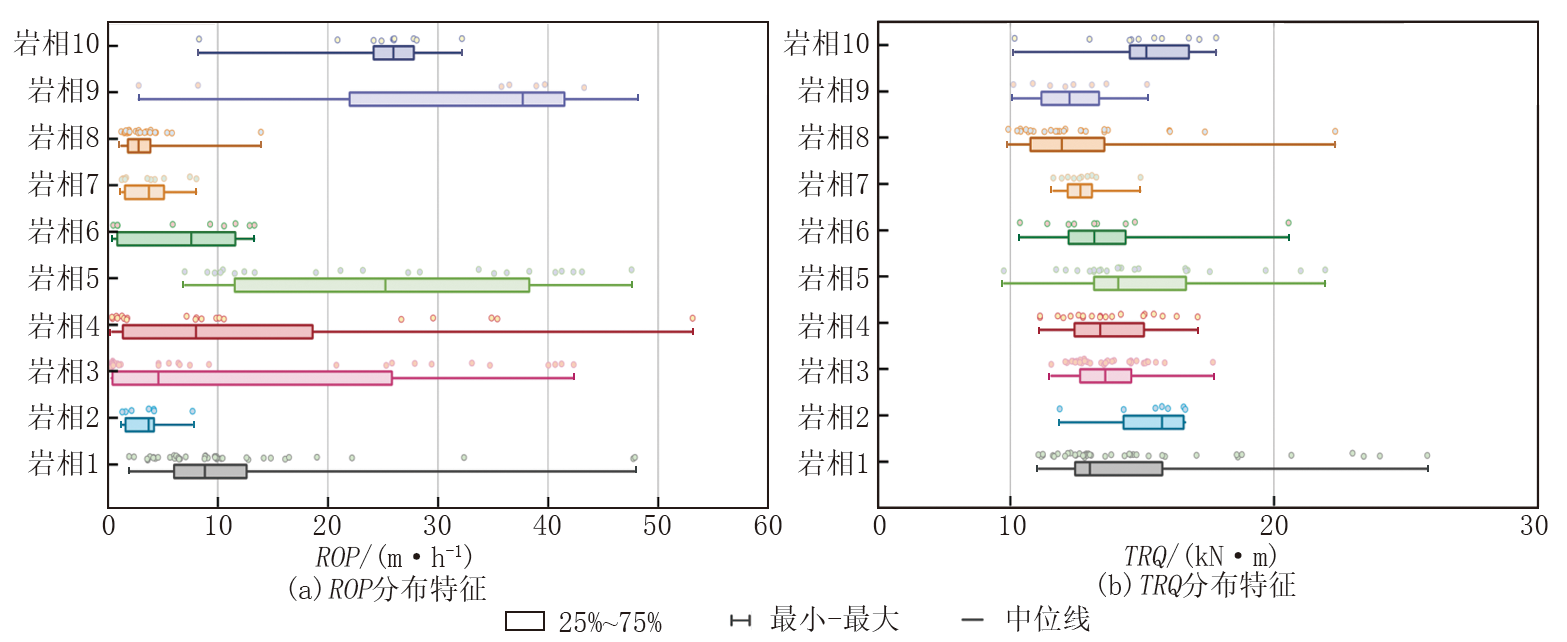 | 图6 不同岩相工程参数响应特征 |
本文共收集研究区123组岩相数据, 并选择基于矿物、岩石热解、工程3类录井方式的10项特征指标(黏土矿物、长英质矿物、碳酸盐矿物、TOC、HI、OSI、ROP、TRQ、S2、S1)用于机器学习训练, 通过多参数融合建模实现岩相识别。
本文分别采用支持向量机(SVM)和随机森林(RF)两种机器学习算法开展页岩岩相识别。相较于卷积神经网络(CNN)等算法而言, 这两种算法能够简化训练流程、减少参数配置, 且在矿物成因分类领域已通过实际验证[27, 28]。
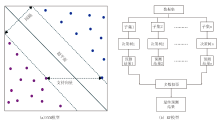
SVM算法依托于统计学习理论框架, 遵循结构风险最小化原则, 其核心是在样本空间或特征空间中构建最优拟合超平面实现样本判别[29]。如图7a所示, 特征图空间中存在多个可能的分类超平面, 但仅有一个最优解(图7a中实线)。最优超平面与非最优平面间的最大距离(即间隔)可有效评估决策边界在训练集上的泛化误差[30]。SVM具有分类能力强大及数据稀疏性等优点, 凭借出色的分类性能与数据稀疏处理能力, 已成为机器学习领域的重要方法, 被广泛应用于地球科学领域, 如地质体智能识别[31]、地质预测系统开发[32]。
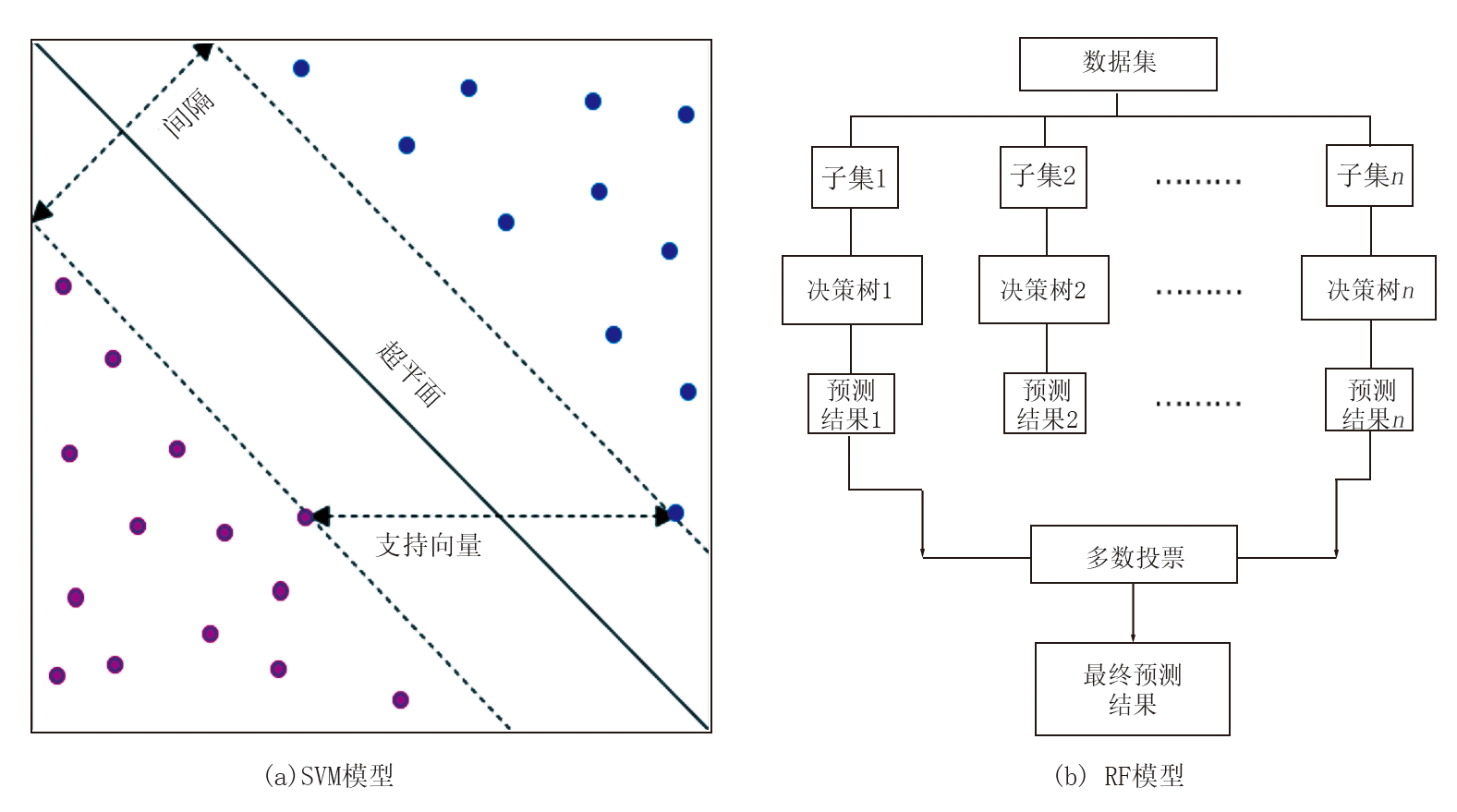 | 图7 机器学习分类模型 |
RF算法是Breiman提出的集成学习方法[33], 其工作原理如图7b所示, 通过Bootstrap重新采样技术构建多个训练子集, 为每个子集单独训练决策树, 最后借助多树投票输出综合预测结果。决策树作为一种基于规则的模型, 是借助二分法逻辑的树状分类器, 通过自主学习数据特征生成规则集, 实现对样本的层级划分。该算法预测精度高, 对异常值与噪声数据表现出强包容度, 且通过决策树多样性组合可有效规避过拟合风险, 这些优势使其在地学领域获得广泛应用, 为复杂地质数据的智能化解析提供了可靠工具。
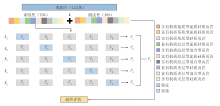
数据集采用分层抽样法按7∶ 3比例划分为训练集与测试集, 以维持各类别样本占比一致。如图8所示, 为验证机器学习模型性能, 对训练集实施五折交叉验证, 将其拆分为5个互斥子集(F1-F5), 每次选取4个子集用于模型训练, 剩余1个子集作为验证集; 该过程循环5次(K1-K5), 确保每个子集均参与验证集。采用支持向量机与随机森林模型, 分别对各子集进行分类预测后, 采用评价指标(P1-P5)量化模型表现, 最终以各项指标的均值(Pt)表征算法性能。此交叉验证机制通过多轮次训练-验证迭代, 可有效提升模型对新数据的适配性[34]。
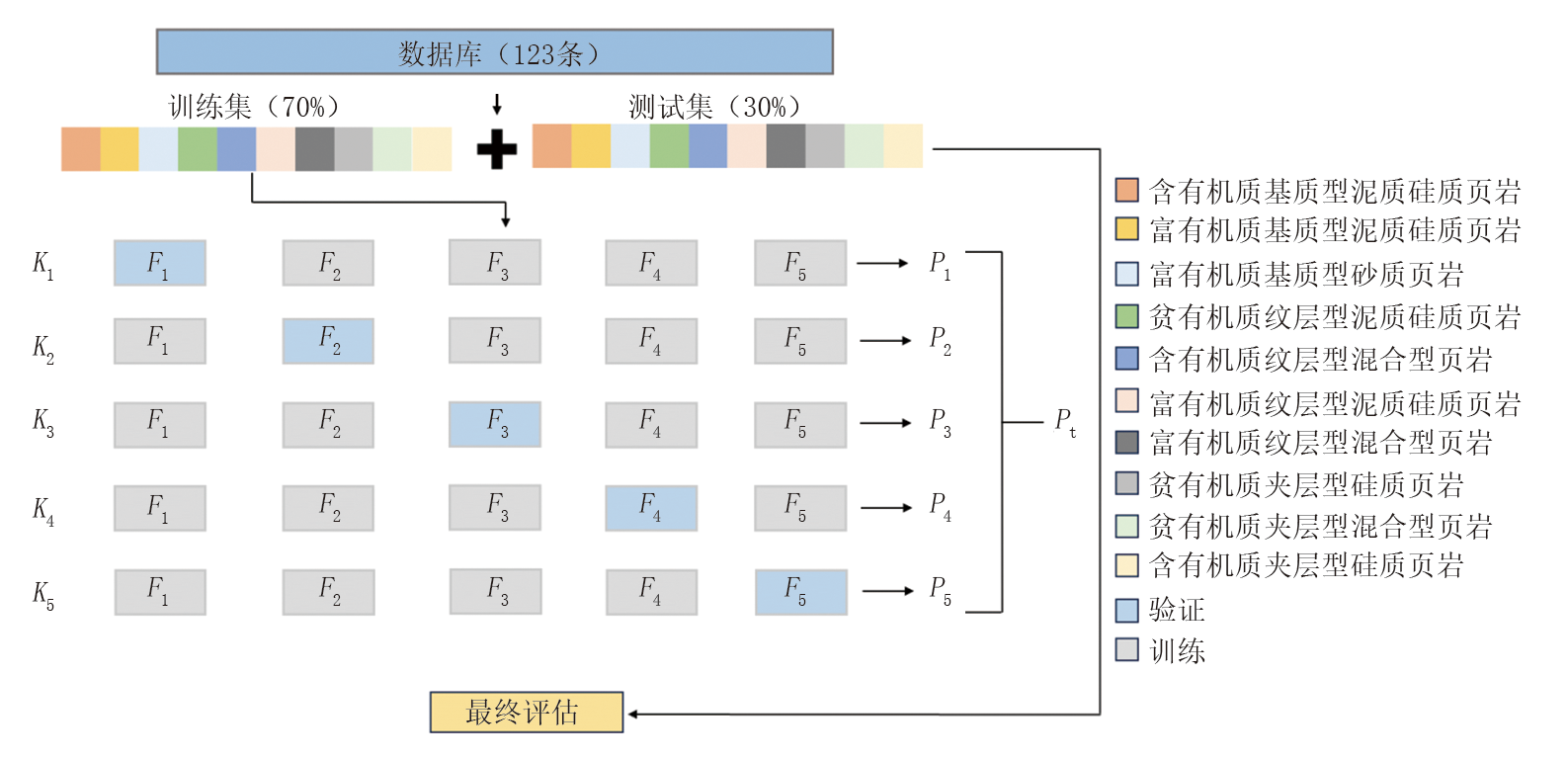 | 图8 数据拆分方案及五折交叉验证工作流程示意 |
本文选用混淆矩阵(Confusion matrix)作为支持向量机与随机森林模型的分类性能评估工具。依托图9所示的矩阵, 从中提取准确率(A)、精确率(P)、召回率(R)及调和平均数(F1值), 以此量化衡量2种机器学习模型的分类表现。4个评价指标的计算公式如下:
式中:TP为目标岩相类且被划分为目标岩相类的样本数; FN为目标岩相类但被划分为非目标岩相类的样本数; FP为非目标岩相类但被划分为目标岩相类的样本数; TN为非目标岩相类且被划分为非目标岩相类的样本数。
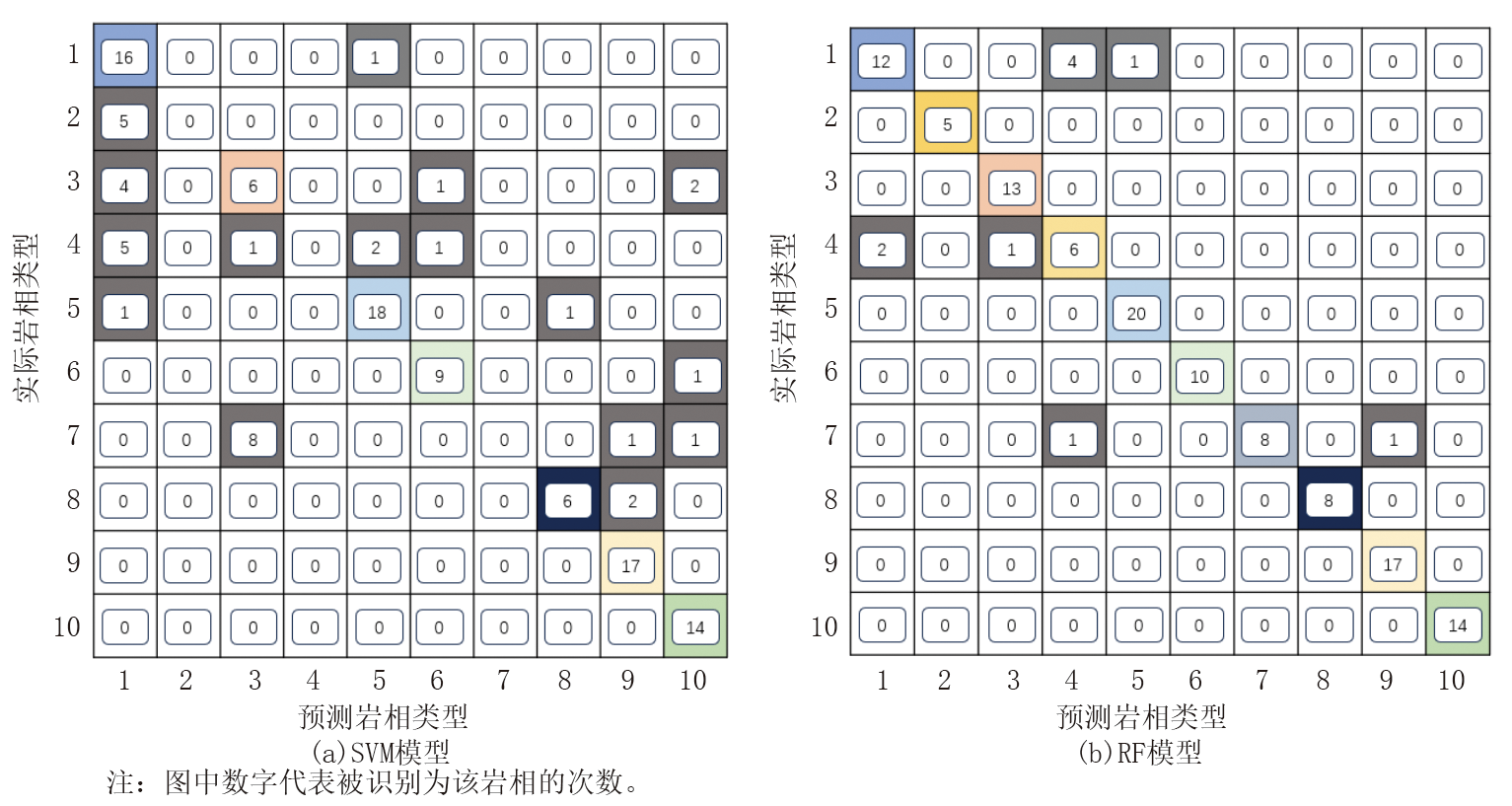 | 图9 混淆矩阵图 |
采用SVM与RF模型对测试集中的10种页岩岩相开展分类识别, 得到涉及这10种岩相的混淆矩阵, 相关模型评价结果如表2所示。从评价结果来看:SVM模型的准确率为0.7, 而RF模型的准确率达0.92, 显著高于SVM模型。且RF模型的精确率、召回率及F1值也明显高于SVM模型。综上, 通过对SVM和RF种算法模型的对比优选, RF模型能够更好地识别测试集内10种类型的岩相。
| 表2 模型评价结果 |
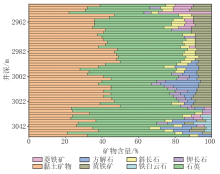
本文以X 6井为实例, 选取10种特征指标, 应用所建立的页岩岩相预测方法对该井2 700~3 050 m井段的页岩岩相进行随钻录井识别, 并与2 818~2 922 m井段的实际岩相数据展开对比分析。如图10所示, 预测岩相剖面与实际岩相剖面在2 818~2 922 m井段内高度一致, 10种岩相类型均被准确识别, 符合率达到了100%, 充分表明本文所建立的预测方法具备较强的稳定性与泛化能力, 在压裂选层优化与储层改造工程实施中, 核心优选岩相应聚焦于富有机质纹层型混合型页岩、富有机质纹层型泥质硅质页岩、含有机质夹层型硅质页岩、含有机质纹层型混合型页岩, 以保障作业针对性与储层改造效率。
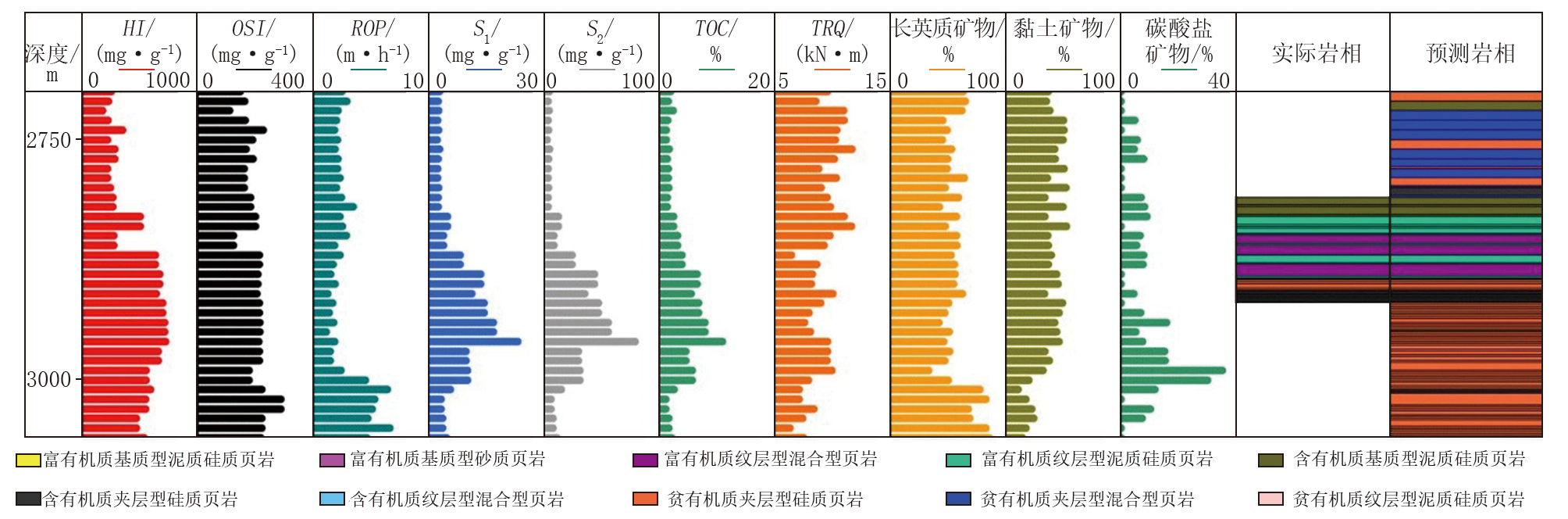 | 图10 X 6井页岩岩相预测结果对比 |
(1)应用“ 有机质丰度+沉积构造+无机矿物含量” 的页岩岩相分类方案, 划分南海涠西南凹陷页岩岩相类型, 主要发育富有机质基质型泥质硅质页岩、富有机质基质型砂质页岩、富有机质纹层型混合型页岩、富有机质纹层型泥质硅质页岩、含有机质基质型泥质硅质页岩等10种岩相类型。
(2)建立了基于SVM和RF算法的页岩岩相随钻录井识别模型, 结果表明RF模型识别准确率更高, 能更有效地对页岩岩相类型进行识别。预测结果与实际结果高度吻合, 表现出较强的稳定性和泛化能力。
(编辑 卜丽媛)
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|