
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
钻井数据智能治理系统的设计与功能实现
[景凌志 , 田雨萌, 郭卫红, 史肖燕, 杨心怡]
, 田雨萌, 郭卫红, 史肖燕, 杨心怡]
, 田雨萌, 郭卫红, 史肖燕, 杨心怡]
|
|


作者简介:景凌志 高级工程师,1978年生,2006年毕业于哈尔滨工业大学计算机科学与技术专业,现在中国石油集团工程技术研究院有限公司从事油气井井筒工程大数据治理及分析工作。通信地址:102206 北京市昌平区黄河街5号院1号楼。E-mail:jinglingzhi@cnpc.com.cn
针对石油钻井工程中数据质量参差不齐、多源异构数据治理困难等问题,设计并实现了一个面向钻井数据的治理系统,以提升数据的一致性、准确性和可用性。系统包含数据管理模块、数据质量评估模块、数据治理模块和视频识别模块。数据管理模块主要实现了数据查询、文件导入、文件下载等功能;数据质量评估模块则通过缺失值、无效值、离群值检测与相关性计算进行质量评估;数据治理模块通过时序分割、工况识别与数据插补,实现对异常数据的修正和补全;视频识别模块通过大模型技术对现场安全提供动态化智能监测。该系统在华北油田试运行表明能够显著提高钻井数据的质量,为后续的分析和决策支持提供可靠的数据基础。
To address the issues of inconsistent data quality and the difficulties in multi-source heterogeneous data governance in petroleum drilling engineering, this paper designs and implements a governance system specifically for drilling data to enhance data consistency, accuracy, and usability. The system consists of the data management module, the data quality assessment module, the data governance module, and the video recognition module. The data management module mainly realizes functions such as data query, file import, and file download.The data quality assessment module evaluates data quality based on missing values, invalid values, outliers detection and correlations calculation. The data governance module corrects and supplements abnormal data through time series segmentation, working condition identification, and data interpolation. The video recognition module employs large model technology to provide dynamic intelligent monitoring for on-site safety. The trial operation of the system in Huabei Oilfield shows that it can significantly improve the quality of drilling data and provide a reliable data base for subsequent analysis and decision support.
钻井工程是石油与天然气开采的关键环节[1], 涉及大量复杂数据, 包括钻井深度、钻头位置、转盘转速、流量和压力等[2]。这些数据的准确性和实时性直接影响钻井作业的安全、效率及成本。然而, 随着数据规模和多样性不断增长, 数据质量管理和治理问题愈发突出, 成为行业亟待解决的挑战。
钻井数据治理涵盖数据质量管理、标准化、安全性保障, 以及整合与共享。随着钻井向自动化与智能化发展, 高效的数据治理成为提升作业效率、优化决策、保障安全的关键, 通过科学治理防止数据冗余、孤岛化、错误和丢失, 进而保障工程决策质量, 规避安全事故与经济损失[3]。因此, 数据治理也是提升管理水平和决策支持能力的必要条件。
近年来, 得益于数据科学、人工智能及物联网的发展, 钻井数据治理逐渐成为研究热点。早期的数据治理主要集中于高质量数据的采集与存储, 随着大数据与机器学习技术的引入, 逐步扩展至数据挖掘与分析, 不仅注重实时监控, 还包括对历史数据的深度分析与预测应用[4, 5]。目前, 企业通过部署数据治理框架来提升数据一致性和准确性, 以支持工程设计、风险评估与过程优化。其中, Hegde等[6]采用随机森林的方法建立了钻井多目标参数模型, 对钻井参数进行学习和计算; 石玉江等[7]构建了基于多学科融合的数据湖, 利用大数据智能解释模型和传统的软件集成, 辅助测井分析人员挖掘隐藏的高价值信息; Bataee等[8]通过搭建神经网络, 建立了钻井作业过程中各个参数之间的关系, 实现了钻井参数实时优化, 最终获得最优的机械钻速。但现有研究仅针对单一数据质量维度进行局部优化, 存在未能建立多参数协同治理机制、对钻井时序数据的非平稳特性和工况转换特征建模不足、较少关注视频数据与传感器数据的跨模态关联治理等问题。
本研究旨在构建全面的数据治理系统, 通过数据清洗、标准化和插补等方法, 结合机器学习和时间序列分析[9], 系统化解决缺失值与异常值等问题, 并创新性集成大模型驱动的视频识别技术实时解析钻井现场作业场景。相比以往仅聚焦数据采集的研究, 本研究覆盖数据全生命周期管理, 为钻井作业提供精准、可靠的数据支持, 从而提升效率与安全性, 并为智能化钻井提供保障。
系统设计包括数据管理、数据质量评估、数据治理、视频识别四大功能模块, 各模块相互协作, 为用户提供完整的功能链路, 涵盖数据处理、分析及结果输出。
数据管理模块主要提供数据查询、文件导入、文件下载等功能, 实现对数据的查询与管理, 为数据的可视化与治理提供支持。
数据查询允许用户通过多种条件筛选和组合查询数据库中的数据。查询接口支持时间范围筛选、字段关键字匹配以及多字段排序等功能, 并提供分页支持以便于大规模数据的浏览。此外, 系统增加了异常处理功能, 可以捕获系统运行时出现的异常, 并以友好的方式返回给用户。
用户通过文件导入功能上传的文件会先经过格式校验, 以确保上传的文件类型和大小范围符合要求。在文件上传后, 系统会对数据进行逐行解析和验证, 包括检查字段格式、数据类型及完整性。对于错误数据, 系统会生成详细的错误日志供用户查看, 同时将有效数据批量写入数据库以提高导入效率。
文件下载提供数据导出的功能, 用户可以将查询结果或模型预测结果以csv格式下载到本地使用。下载操作会被系统记录, 包括下载时间、用户身份及文件名, 以便后续审计或统计分析; 后端通过动态生成文件并提供临时链接, 满足用户多样化需求。
数据质量评估的设计目标是通过定量指标来衡量数据的完整性与可靠性, 为后续的数据处理与建模提供坚实基础。从缺失值、无效值、离群值等多个维度对数据进行质量检查, 并结合相关性分析来深入理解数据间的关系特征, 从而建立全面的数据质量评估体系, 确保分析结果的准确性和模型的稳健性。
数据治理模块作为本系统的核心组成部分, 通过一系列算法模型对原始钻井数据进行深度处理与质量提升。该模块涵盖了时序分割、工况识别与数据插补三大关键环节:首先利用时序分割算法将连续钻井数据划分为具有工程意义的段落; 然后通过神经网络模型识别不同工况状态; 最后采用生成式对抗网络进行高精度数据插补, 有效修复异常数据与缺失值。通过上述多阶段协同处理, 系统显著改善了数据的完整性、一致性与可用性, 为钻井过程的智能分析与决策优化提供了高质量的数据支撑。
针对钻井场景视频数据的多维度分析需求, 本系统采用基于Transformer架构的时空联合建模技术, 通过动态帧采样、多模态特征融合与轻量化推理优化, 实现复杂工业场景下的高精度视频语义解析。模型以Video Swin Transformer为核心骨干网络, 通过分层时空注意力机制提取视频序列的局部与全局特征, 并引入时序位移模块(Temporal Shift Module)增强连续帧间的动作关联性建模能力。为适配钻井场景中人员行为、设备状态等小目标检测需求, 模型采用级联式检测头设计:第一级基于YOLOv 8框架完成实时目标定位与粗粒度分类; 第二级通过轻量化ViT(Vision Transformer)子网络对关键区域进行细粒度特征提取, 实现防护装备合规性(如安全帽佩戴角度、手套完整性)及设备异常状态(如管线渗漏、仪表读数偏差)的高置信度识别。
数据质量评估旨在识别数据潜在问题, 为后续清洗、转换与特征工程提供依据, 从而提升数据的一致性与可用性。
缺失值检测是数据质量评估的核心任务之一, 旨在识别数据集中预期字段或数据点为空或未填充的情况。缺失值的存在可能导致数据分析结果偏差, 进而影响模型的性能。对于检测到的缺失值, 本模块支持多种处理方法, 包括填充、删除和插值, 以便根据实际情况选择合适的处理方案, 最大限度减少其对数据建模的不利影响。对于数据整体而言, 缺失值比例是指缺失值行数量与总行数的比值。
无效值是指数据集中不符合预期范围或格式的异常数据点, 例如数值字段中的非数字字符、不合理的数值范围或逻辑上不可能的值。模块通过设定合理的阈值或规则来自动过滤这些无效数据, 确保数据的有效性与一致性。无效值的检测不仅提高了数据的质量, 同时为后续分析和建模提供了更为可信的数据基础。对于数据整体而言, 无效值比例是指无效值行数量与总行数的比值。
离群值检测用于识别与数据集中大多数数据点显著不同的异常数据点, 这些离群点可能源于数据录入错误、异常操作或极端情况。离群值的存在可能对整体数据分析产生误导, 因此本模块提供剔除、替换和标记等多种处理选项, 以减少离群值对分析结果的影响。合理的离群值处理有助于提升模型的鲁棒性和预测精度。对于数据整体而言, 离群值比例是指离群值行数量与总行数的比值。
相关性指标用于衡量特征间及特征与目标变量的相关性, 是识别数据模式和异常的重要工具。常用指标包括皮尔逊相关系数和斯皮尔曼等级相关系数, 可揭示数据关联性和潜在规律, 从而更精准地识别异常工况。
在钻井作业中, 仅依赖单一特征进行异常检测可能导致误判。例如, 转盘转速突然增大时, 仅观察钻速可能无法判断异常, 因为钻速变化可能是操作条件正常波动所致。为此, 异常检测需结合相关特征进行综合分析, 以避免将正常波动识别为异常情况。
皮尔逊相关系数的计算公式如下:
式中:
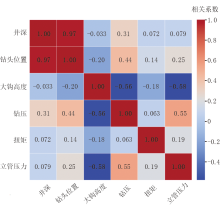
本研究选取井深、钻头位置等6个特征参数并计算相关性, 相关性矩阵如图1所示。通过计算6个关键钻井参数间的皮尔逊相关系数, 揭示出参数间存在显著的关联差异。例如, 井深与钻头位置呈现明显的正相关, 说明参数在钻井过程中具有协同变化的趋势; 大钩高度与钻压、立管压力存在负相关关系, 显示出其具有反向协同的变化特征。这些内在关联性表明, 所选的6个参数能够有效捕捉钻井状态的变化, 从数据层面验证了其作为后续时序分割与工况识别模型输入特征的合理性和充分性。
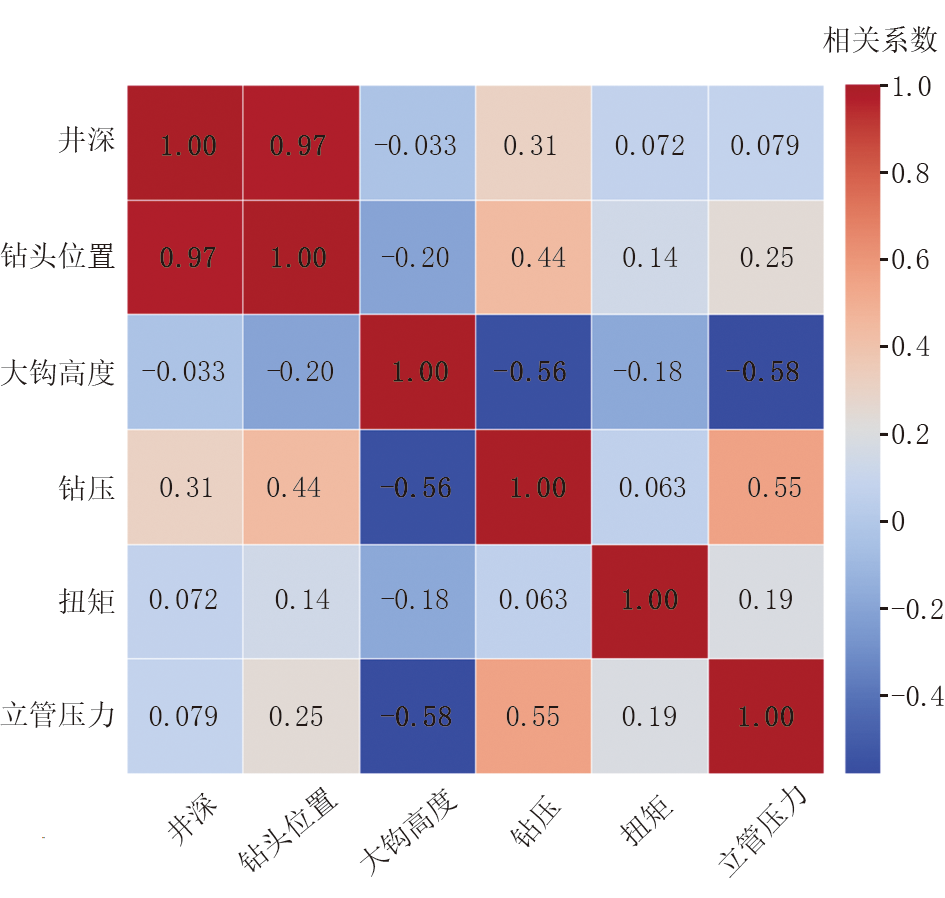 | 图1 钻井参数相关性矩阵 |
本系统的数据治理模块是实现钻井数据质量提升的智能核心, 其效能依赖于一系列紧密衔接的底层算法。这些算法构成了一个从分割、识别到修复的完整技术链条。本节将详细阐述时序分割、工况识别与数据插补三大关键技术的原理及模型设计。
研究表明, 相较于其他钻井参数, 井深、钻头位置、大钩高度、钻压、扭矩和立管压力6个参数与钻井工况特征之间呈现出更为显著的相关性, 在不同工况下呈现规律性, 反映设备运行状态。因此, 选取这6个参数为特征输入, 通过数据优化筛选, 减少冗余特征, 避免过拟合, 提高模型训练效率和预测准确性。
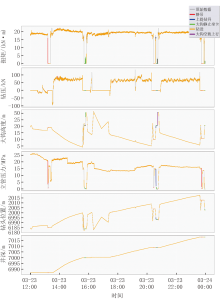
时序分割根据数据变化点将时序数据划分为多个阶段[10]。首先, 清洗数据, 去除冗余字段, 提取目标相关特征; 然后, 使用z-score方法标准化, 将特征值转换为均值为0、方差为1的标准数据, 消除量纲差异影响; 最后, 通过滑动窗口计算特征均值, 并用变化点检测算法识别关键点, 将时序数据切分为多个片段。这些片段代表不同工况状态, 为后续分析与预测奠定基础。分割结果如图2所示。
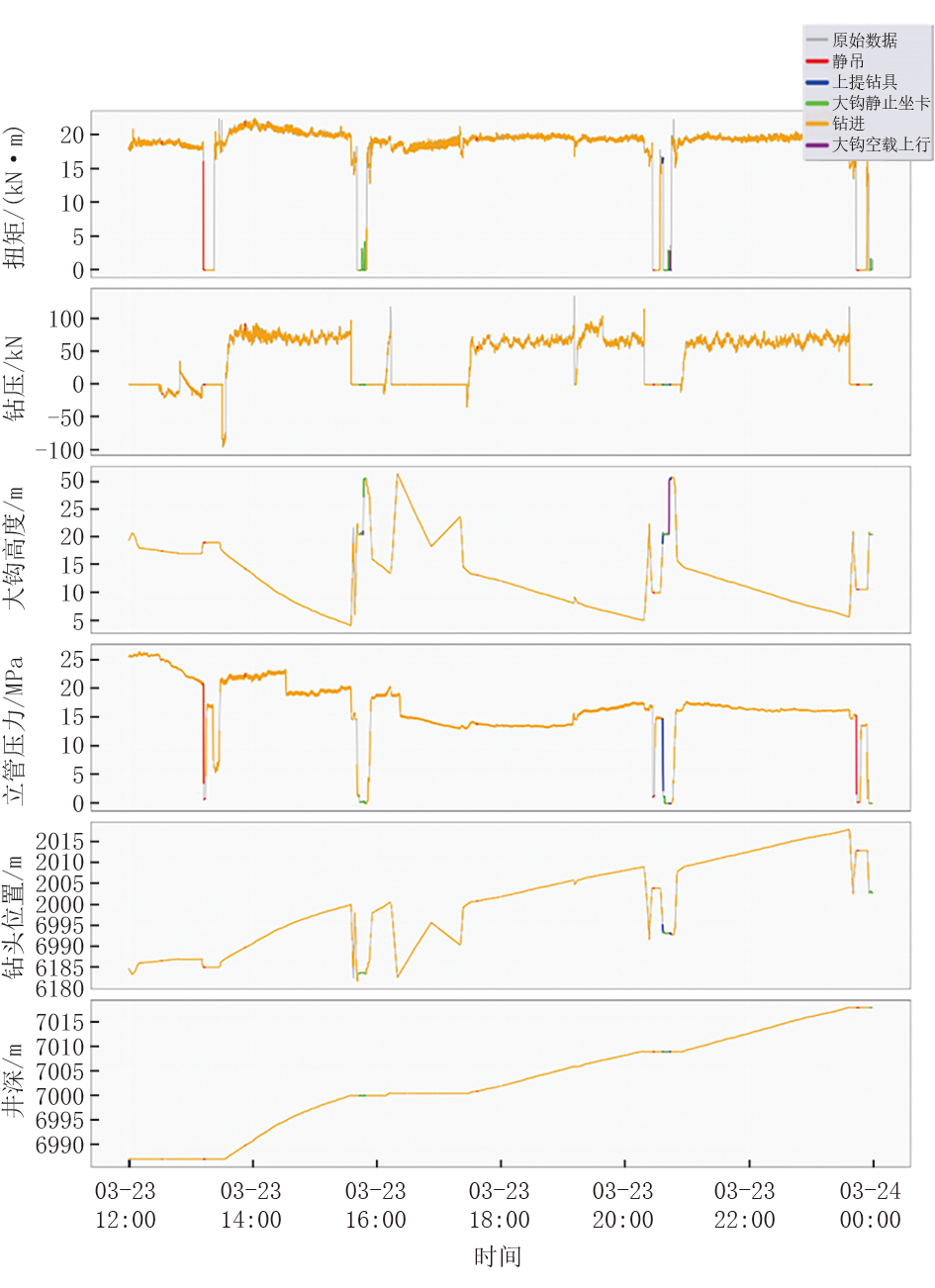 | 图2 时序数据分割图 |
通过这种方式, 数据的整体结构被分割成多个具有不同特征的片段, 每个片段对应于时间序列中的一个特定钻井状态或阶段。这种分割结果为后续的深度分析和预测提供了基础, 有助于更好地理解钻井数据的内在规律和变化趋势。
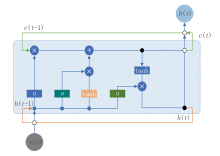
在完成时序数据分割后, 切分得到的每个片段将作为独立样本输入到基于神经网络的工况识别模块[11]中。每个分割片段以多个关键钻井参数(如井深、钻压、钻头位置等)构成特征向量, 作为模型的输入, 然后采用长短期记忆网络(LSTM)[12]对每个时间序列片段进行处理。模型最终输出每个片段的工况状态标签及其对应的概率分布。该方法能够准确识别钻井作业过程中的不同状态, 辅助优化钻井过程。循环神经网络结构如图3所示, 其中:c(t-1)、c(t)分别表示上一时刻、当前时刻的细胞状态(记忆载体); h(t-1)、h(t)分别表示上一时刻、当前时刻的隐藏状态(信息输出); x(t)表示当前时刻的输入特征向量; “ σ ” 节点为sigmoid激活函数(生成0~1的权重系数); “ tanh” 节点为双曲正切函数(生成-1~1的归一化输出); “ × ” 为门信号与向量的逐元素相乘; “ +” 为将更新后的信息合并到新的细胞状态中。
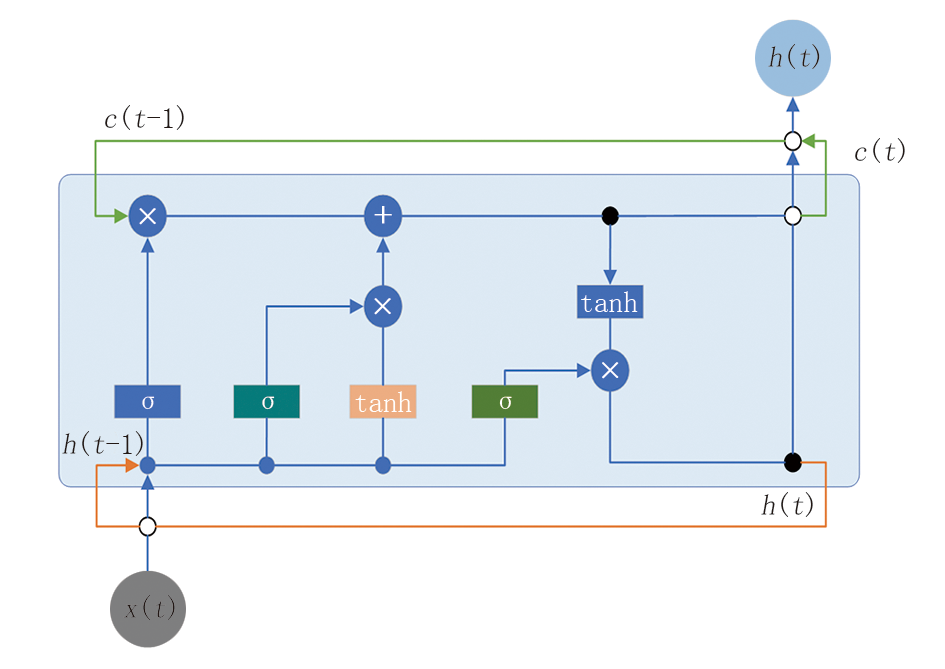 | 图3 循环神经网络结构 |
数据插补阶段是处理异常数据和缺失值的关键环节。首先进行数据清洗, 消除明显错误或不完整的数据, 同时通过特征工程提取与钻井过程相关的重要特征; 接着, 采用卷积神经网络(Conv-WGAIN)[13]对缺失值进行插补, 该模型通过对抗训练优化生成器, 利用Wasserstein距离作为损失函数, 以生成更真实的插补数据; 最终, 插补后的数据用于补充缺失值, 提升数据集的完整性和一致性, 确保后续分析和预测的准确性。
为展示系统的运行效果, 分别对数据管理、数据质量评估、数据治理与视频识别4个核心模块的实现进行说明。
该模块分为数据概览和数据查看两部分。
数据概览部分可以导入、下载数据以及查看全部数据样本的统计信息。数据统计以井位为单位进行汇总, 展示了每口井的ID、总数据量, 以及数据起始时间。导入数据时需要导入csv格式的数据文件, 系统在收到导入的数据后会根据数据井的ID将新数据记录到对应的数据库中保存。点击查询后, 将从数据库中实时汇总数据, 并展示出来。对于下载功能, 查询成功后, 下载框中会显示已有井的ID, 默认时间范围为全部时间。
数据查看部分分为两个区域, 左侧为数据道渲染区, 右侧为控制面板, 如图4所示。控制面板可以控制需要渲染的数据道的数据来源和数据量等参数, 对该页面配置项的解释如表1所示。
 | 图4 数据查看可视化界面 |
| 表1 系统配置信息的解释 |
数据质量评估模块中的缺失值检测界面如图5所示。该界面展示了数据预处理过程中对缺失值的量化评估结果, 为后续的工况识别、数据插补等治理步骤提供依据。
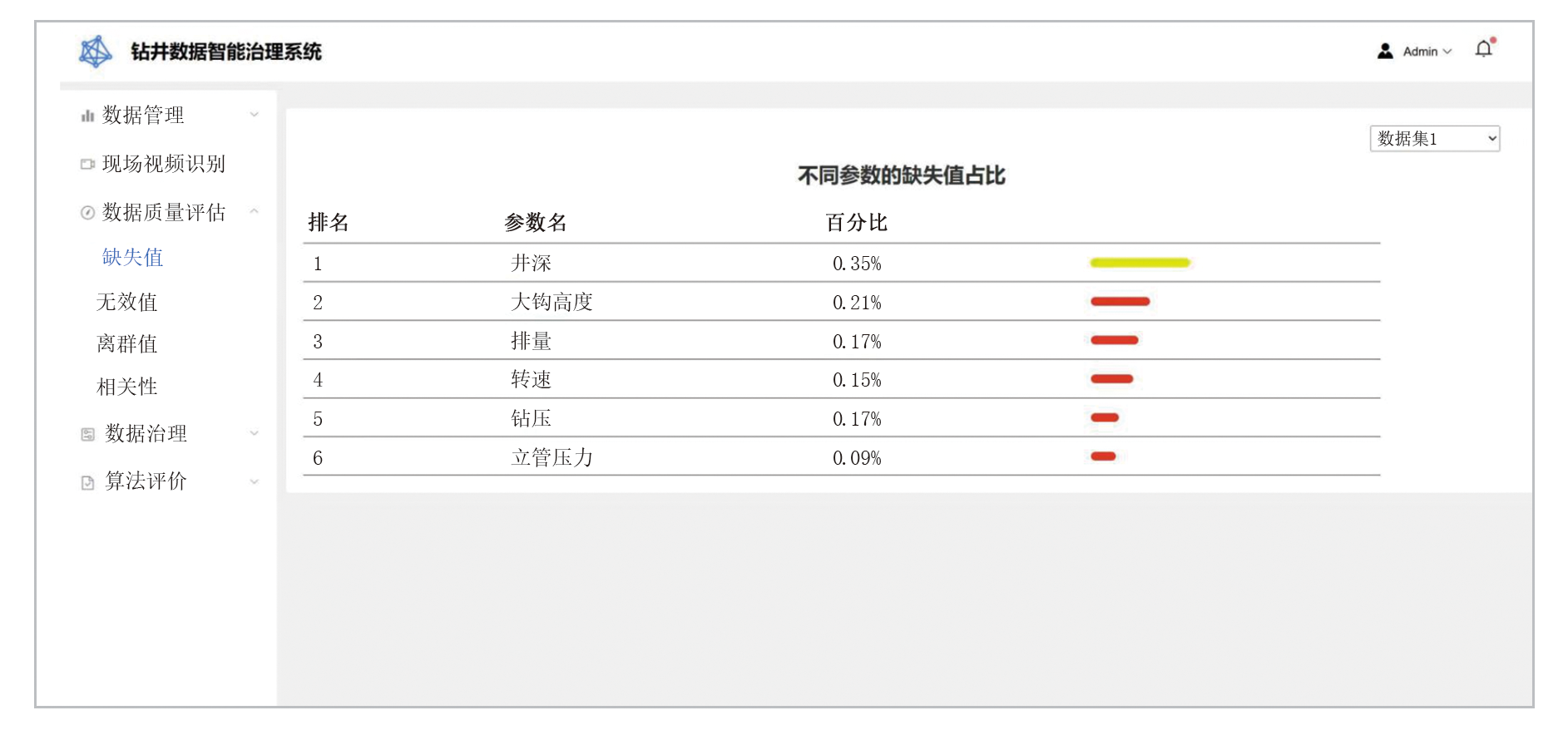 | 图5 缺失值检测可视化界面 |
该模块对数据进行展示, 用户可直观浏览数据, 根据导入的数据集进行时序分割并将分段结果清晰呈现, 进而对其工况进行智能识别, 再完成数据的修正与插补。可视化界面如图6、图7所示。
 | 图6 数据展示可视化界面 |
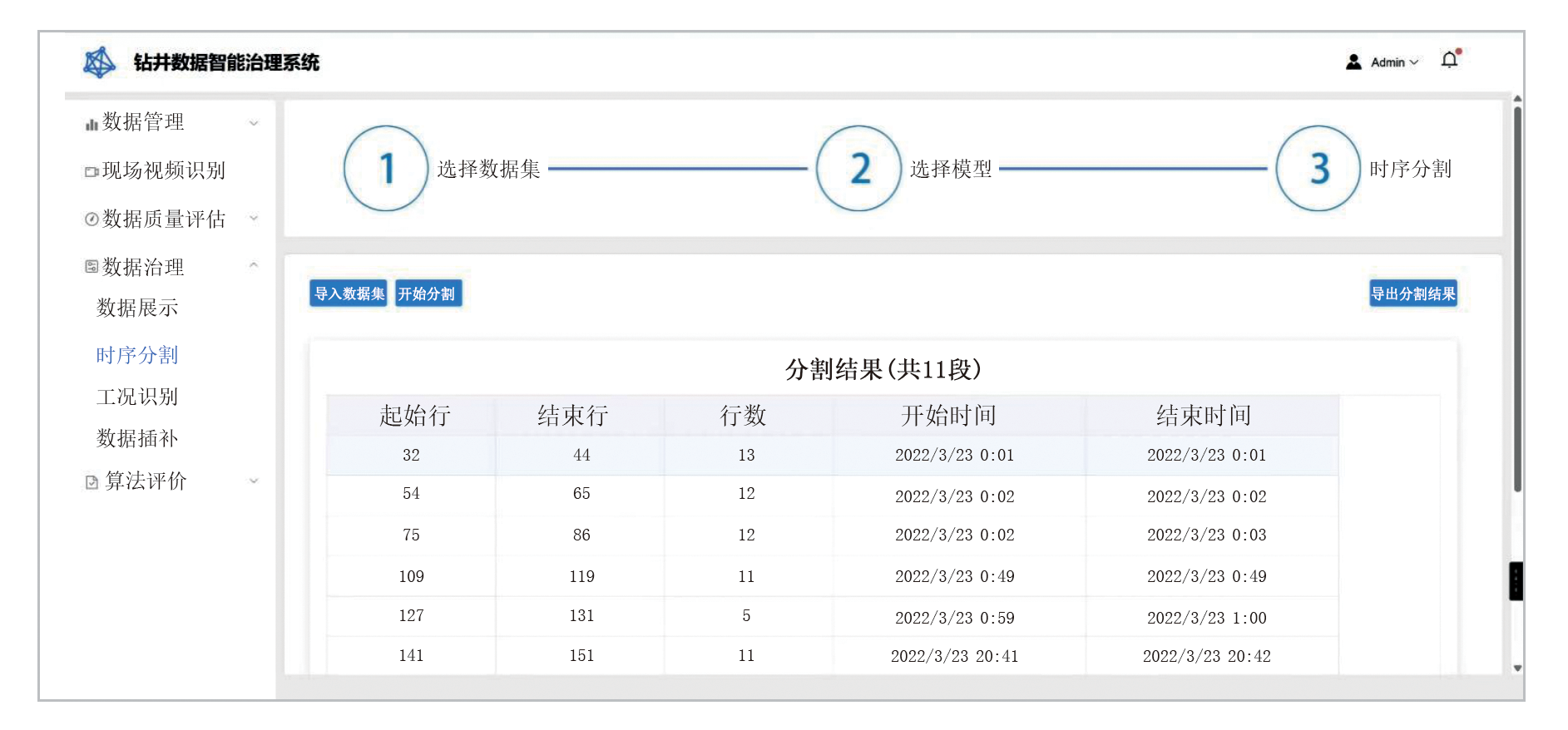 | 图7 时序分割结果可视化界面 |
该模块采用左右分栏式布局。左侧为视频实时预览区, 支持播放、暂停及停止操作, 可显示指定时间节点的钻井现场监控画面; 右侧为视频识别大模型的输出展示区, 通过结构化文本同步呈现算法识别的多维分析结果, 包括人员行为、防护装备合规性、环境安全隐患、设备状态等关键检测项, 为现场安全提供动态化智能监测支持, 显著提升了风险预警的时效性和监管效率。
数据质量评估作为整个治理过程的基础环节, 在华北油田试运行期间对数据进行了系统评估。首先, 针对数据中的缺失值、无效值及异常值进行检测, 通常能够有效识别出数据中存在的缺失值、无效值和异常值。统计数据显示, 缺失值、无效值及异常值平均占比约为15%。通过数据补齐与异常校正手段, 这些问题得以有效处理, 显著改善了数据的完整性与一致性。
此外, 采用时序分割技术将连续钻井数据划分为具有工程意义的工况段, 有效提升了数据趋势与模式识别的准确性。工况识别模块基于实际作业数据, 成功识别多种钻井状态, 分类准确率达到92%, 为钻井参数优化提供了可靠依据。试运行结果表明, 该系统在提升数据质量与分析效率方面成效显著。
针对石油钻井工程中数据质量参差不齐与多源异构数据治理困难的问题, 本文开发设计了一套钻井数据智能治理系统。该系统在华北油田实际试运行过程中表现出良好的应用效果, 通过集成数据管理、数据质量评估、数据治理与视频识别模块, 使数据整体质量显著提升, 为钻井优化与决策提供了坚实的数据基础。未来还将进一步拓展多模态数据融合与轻量化部署能力, 推动钻井数据智能治理系统在更广泛工业场景中的落地应用。
(编辑 卜丽媛)
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|