

沈文建 , 魏庆阳, 方振东, 王岩, 邓贵柏
, 魏庆阳, 方振东, 王岩, 邓贵柏
中法渤海地质服务有限公司
中图分类号: TE132.1
文献标识码: A
收稿日期: 2019-11-11
网络出版日期: 2019-12-25
版权声明: 2019 《录井工程》杂志社 《录井工程》杂志社 所有
作者简介:
作者简介:沈文建 工程师,1981年生,2004年毕业于南京师范大学统计学专业,现在中法渤海地质服务有限公司从事大数据分析及信息化系统建设工作。通信地址:300452 天津市滨海新区东沽石油新村548信箱中法地质。电话:(022)66915016。 E-mail :shenwj@cfbgc.com
展开
摘要
随着数据的爆发式增长和大数据技术的不断发展,数据挖掘技术已成为数据分析和知识发现的重要手段。为拓展数据挖掘技术在录井方向上的系统应用思路,在调研、总结其他领域数据挖掘知识及应用方法的基础上,尝试使用渤海油田地化录井数据构建原油性质判别模型,实现了数据挖掘技术在录井解释中的应用,并在特征工程、模型训练等方面积累了经验。构建原油性质判别模型的过程及模型预测结果表明,使用合理的步骤、参数及算法进行数据挖掘,可有效、快速地进行录井解释,数据挖掘技术值得更深入地研究及开发应用。
关键词:
近几十年来,随着定量荧光、核磁共振、地化等技术纷纷引入录井领域,录井技术已经发展成为集机械、化学、电、磁等专业理论于一体的综合技术[1]。录井技术不断发展的同时,勘探开发难度也日益增大,储集层物性及油气水关系解释难度加大,且工程条件常出现“复杂情况”。在复杂储集层、复杂油水关系、复杂井况条件下,更需进一步发挥录井技术在油气水解释评价和钻井安全服务中的先导作用。然而,目前录井解释方法仍以经验图板、经验参数为主,录井解释严重依赖解释人员经验,录井数据中所蕴含的重要信息并没有被充分挖掘[2]。数据挖掘技术作为多维数据分析和知识发现的重要手段,在录井行业应用中并没有得到充分利用,为了更有效、更充分地利用录井数据,笔者从录井解释应用角度出发,探索数据挖掘技术的应用思路和方法。
数据挖掘就是从大量的数据中发现隐含的、有价值的规律和知识[3],常用于解决分类、预测等问题,主要包括机器学习和数据库两项技术,机器学习用于分析数据,数据库用于管理数据。算法是机器学习的核心,包括决策树、逻辑回归、朴素贝叶斯、K最近邻算法、支持向量机、神经网络等算法,分为监督学习、无监督学习、半监督学习等类型。
数据挖掘工具众多,常见的有RapidMiner、R、SPSS、WEKA、Matlab、Python等,本次研究采用Python及其SKlearn算法库开展。
一般而言,数据挖掘需经历以下步骤:
(1)目标确定:分析业务需求,确定挖掘目标。
(2)数据获取:分析建模所需数据并进行收集。
(3)数据预处理:检查数据质量,对数据进行整理、清洗、标准化处理。
(4)建立模型:确定训练集、验证集和预测集数据,选择特征参数,选择算法、调整参数训练,达到训练目标。
(5)模型验证:评价模型并进行实例验证,判断是否满足数据挖掘目标。
(6)模型部署:将经过验证的模型应用于真实环境,实时跟踪和维护模型。
在整个数据挖掘过程中,常常需要多个步骤迭代进行,如数据预处理、建立模型和模型验证三个步骤循环执行多次;同一步骤的子过程也常迭代进行,如在建模过程中,选择特征参数、调整模型参数和训练模型反复执行。
录井解释指以录井资料为主,以测井、测试等资料为辅做出的综合解释,包括地层岩性剖面建立、油气水层解释、异常地层压力解释和钻井异常事件解释,其中油气水层解释包含原油性质判断和流体类型识别两项内容。本文使用渤海油田地化录井数据构建原油性质判别模型为例,介绍数据挖掘过程。
渤海油田油藏类型多样,同一口井往往会钻遇不同油质的油藏,原油性质难以准确快速判别[4],而不同油质的储集层特征存在较大差异,故应采用不同的评价方法。油质判断对于油气水层快速解释有重要意义,鉴于油质判断的重要性及其存在一定难度,特开展数据挖掘研究,寻找录井数据与油质间的关联规律,并构建油质判别模型。结合井场经验,确定本次数据挖掘目标为模型正确率达到90%、预测正确率达到85%。
油质主要受原油化学组成和构成影响,而地化录井技术可用于检测储集层中的烃类含量,相对气测、核磁共振等其他单项录井技术,地化录井对于原油性质预判具有先天优势,因而选用地化录井数据挖掘油质判断规律。由于油质信息只能由测试数据标定,需将数据范围进一步限定于测试井。按照上述思路收集数据,共获取45口井数据,包括测试数据、岩石热解分析数据、热解气相色谱数据。
获取原始数据后对数据进行预处理,步骤如下:
(1)拼接岩石热解分析数据和热解气相色谱数据,再将井名、样品深度以及样品类型相同的行数据合并。
(2)根据井名、样品深度在测试数据对应井、对应深度范围内查找密度和测试结论信息,并补充至拼接后的地化数据表。
(3)剔除非油层、不完整、重复行、重复列、数值无变化列及非数值列等数据。
(4)将密度信息转换为油质信息,规则如下:
轻质油:原油密度范围为0.83~0.87 g/cm3。
中质油:原油密度范围为0.87~0.92 g/cm3。
重质油:原油密度范围为0.92~1.00 g/cm3。
2.4.1 样本分类
训练集、验证集和预测集数据分类思路如下:
(1)训练集、验证集为2018年之前41口探井,预测集为2018年4口新钻探井。
(2)训练集样品类型为井壁取心和岩心,验证集样品类型为岩屑。
2.4.2 特征选择
预处理后参数包括井深、nC12-nC38、Pr、Ph、主峰碳数、Pr/Ph、∑nC30+/∑nCn、S0、S1、S2、Tmax、Pg、GPI、∑nC21-/∑nC22+、(S0+S1)/S2等50多个参数,由于关联性不强的参数会影响模型预测准确性,建模前需选择特征参数。
特征选择常用算法有过滤式、包裹式和嵌入式三种。与过滤式相比,包裹式计算需耗费更多的CPU及内存资源,但特征结果更准确;嵌入式主要用于在模型既定的情况下选择提高模型准确性的参数,相对应用较少。由于本次挖掘数据量较小且模型不确定,只选择包裹式算法进行数据选择。包裹式运算Python核心代码如下:
estimator = LinearSVC()#使用支持向量机作为学习器
selectorRFE = RFE(estimator = estimator,n_features_to_select = 6)#使用RFE实现包裹式特征选取。其中,学习器为支持向量机,被选择的特征参数数量为6个
selectorRFE.fit(xTrainD, yTrainD)#使用训练集训练RFE数据选取模型
采用RFE包裹式算法进行特征选择,优选出井深、∑nC21-/∑nC22+、S2、(S0+S1)/S2、Ph/nC18、主峰碳数6个参数。
2.4.3 算法训练
决策树是一种以树结构形式表达的分类和预测分析模型,属于有监督的学习方法,其输出结果为一系列简单实用的规则,具有速度快、准确度高等特点[5]。油质判别需要预测油质类型(轻质油、中质油和重质油),学习类型属于分类任务和监督学习,且现阶段数据量较小,所以选择CART分类决策树算法进行建模。
决策树包括回归决策树和分类决策树,分类决策树Python核心代码如下:
clf = tree.DecisionTreeClassifier(criterion='entropy',splitter='best',max_depth=4)#建立分类决策树模型,切分评价标准是熵,采用最优切分,其最大深度为4层
clf = clf.fit(xTrainD, yTrainD)#模型训练
在模型训练过程中,首先确定切分评价标准和切分方式,切分评价标准包括熵及基尼系数两种,切分方式包括最优切分和随机切分两种。在训练集、测试集及其他参数不变的情况下,使用熵和最优切分的组合策略拟合程度最高,因而选用熵和最优切分作为模型参数。
除切分评价标准和切分方式外,决策树深度对模型精度影响较大。决策树越深,模型越复杂,预测精度越高,但可能过拟合。在训练集、测试集及其他参数不变的情况下,决策树深度大于4层后,随着深度的增加,符合率略有提高,但提高缓慢,为防止过拟合,最终将决策树深度确定为4层。决策树深度为4层时,训练符合率为96.7%,测试符合率为92.3%,满足数据挖掘要求。
2.4.4 模型业务评估
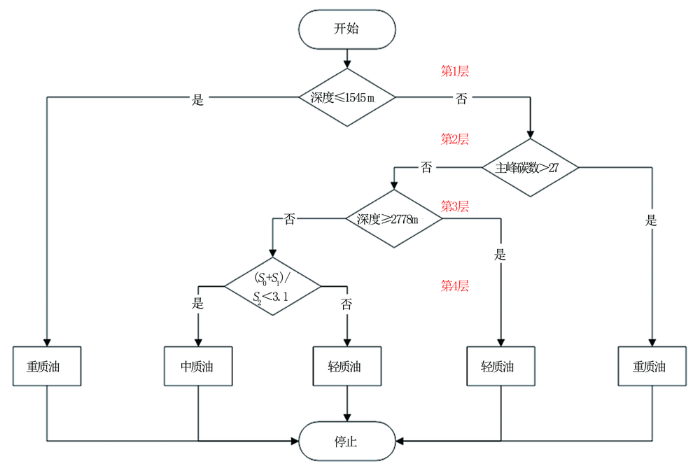
将油质判断分类决策树模型输出并去除影响很小的枝叶后得到如下模型(图1),该模型包含的判断规则如下:
(1)深度小于1 545 m或主峰碳数大于27的样品为重质油。
(2)深度在1 545~2 778 m之间且(S0+S1)/S2小于3.1的样品为中质油。
(3)深度大于2 778 m的样品为轻质油。
(4)深度在1 545~2 778 m之间且(S0+S1)/S2大于3.1的样品为轻质油。
2.4.5 三个油质分类判断参数
油质判断分类决策树主要使用样品深度、主峰碳数和(S0+S1)/S2三个参数,具体分析如下:
(1)强烈的断裂活动与微生物降解是渤海海域新近系稠油油藏形成的主要原因,而温度限定了生物降解的范围[6]。生物降解常发生在温度低于80℃地层,在渤海油田对应深度约为2 500 m以下。从数据上反映,深度1 545 m以上为重质油区,深度2 778 m以下为轻质油区,深度1 545~2 778 m之间为轻质油、中质油、重质油混杂区。
(2)相比高分子量的正构烷烃,低分子量正构烷烃更容易被细菌降解,生物降解程度越高油质越重,主峰碳数是气相色谱检测系列中谱峰面积最大的正构烷烃,则随着主峰碳数变大油质变重。
(3)S0、S1、S2分别代表原油中的轻质、中质及重质组分[7],计算参数(S0+S1)/S2可表征原不同油质组分含量的比值。
通过分析认为,样品深度、主峰碳数和(S0+S1)/S2三个参数可以用于油质判断,通过数据挖掘得出的规律存在合理性。
使用油质判断分类决策树模型对BZ-1、PL-1、KL-4、KL-6四口井进行判断,油质判别均符合测试结果(表1),符合率100%,预测正确率高于85%,模型部署后可进行实际应用。
表1 模型预测验证情况
| 井名 | 深度/m | 主峰碳数 | (S0+S1)/S2 | 原油密度/(g·cm-3) | 油质 | 符合情况 |
|---|---|---|---|---|---|---|
| BZ-1 | 1 297 | nC32 | 0.856 258 2 | 0.950 9 | 重质油 | 符合 |
| BZ-1 | 1 315 | nC30 | 1.072 951 1 | 0.950 9 | 重质油 | 符合 |
| BZ-1 | 1 320 | nC30 | 0.743 872 8 | 0.950 9 | 重质油 | 符合 |
| BZ-1 | 1 552 | nC30 | 0.806 790 6 | 0.993 4 | 重质油 | 符合 |
| BZ-1 | 1 558 | nC31 | 0.792 102 8 | 0.993 4 | 重质油 | 符合 |
| BZ-1 | 1 565 | nC31 | 0.706 933 7 | 0.993 4 | 重质油 | 符合 |
| BZ-1 | 1 569 | nC31 | 1.052 546 3 | 0.993 4 | 重质油 | 符合 |
| KL-4 | 1 301 | nC31 | 0.669 217 2 | 0.941 9 | 重质油 | 符合 |
| KL-4 | 1 304 | nC30 | 0.792 611 6 | 0.941 9 | 重质油 | 符合 |
| KL-4 | 1 559 | nC23 | 0.854 536 1 | 0.878 0 | 中质油 | 符合 |
| KL-4 | 1 571 | nC17 | 0.114 028 5 | 0.878 0 | 中质油 | 符合 |
| KL-4 | 1 600 | nC23 | 1.605 191 7 | 0.878 0 | 中质油 | 符合 |
| KL-4 | 1 601 | nC20 | 0.381 514 2 | 0.878 0 | 中质油 | 符合 |
| KL-4 | 1 605 | nC19 | 0.309 701 2 | 0.878 0 | 中质油 | 符合 |
| KL-4 | 1 607 | nC23 | 0.622 346 3 | 0.878 0 | 中质油 | 符合 |
| KL-6 | 1 518 | nC31 | 0.765 801 2 | 0.967 7 | 重质油 | 符合 |
| PL-1 | 1 242 | nC31 | 0.551 048 8 | 0.963 4 | 重质油 | 符合 |
| PL-1 | 1 245 | nC31 | 0.744 540 8 | 0.963 4 | 重质油 | 符合 |
| PL-1 | 1 249 | nC31 | 0.685 151 2 | 0.963 4 | 重质油 | 符合 |
| PL-1 | 1 507 | nC30 | 0.908 698 9 | 0.950 2 | 重质油 | 符合 |
| PL-1 | 1 513 | nC31 | 0.846 246 0 | 0.950 2 | 重质油 | 符合 |
| PL-1 | 1 519 | nC31 | 0.651 060 7 | 0.950 2 | 重质油 | 符合 |
| PL-1 | 1 527 | nC31 | 0.714 591 5 | 0.950 2 | 重质油 | 符合 |
通过应用数据挖掘技术构建油质判别模型,初步完成了数据挖掘技术在录井解释方面的应用探索,根据理论知识和实践经验得到以下结论:
(1)数据挖掘吸纳了诸如统计学、机器学习、数据库、信息检索等领域的大量技术,适合应用于录井领域,数据挖掘包括目标确定、数据获取、数据预处理、建立模型、模型验证、模型部署等步骤,部分步骤需根据具体实践反复迭代。
(2)数据挖掘应由数据和专业两方面配合同时驱动,机器学习与录井专业知识应紧密结合,在专业分析的基础上进行数据预处理、算法选择、参数调整等工作。
(3)通过应用RFE包裹式特征选取算法和CART分类决策树算法,快速优选出样品深度、主峰碳数和(S0+S1)/S2三个参数,建立渤海油田原油性质判别模型,并使用新井数据验证该模型的有效性。实例证明,数据挖掘技术可有效、快速地应用于录井解释,建议在录井领域进行更深入的开发研究。
(编辑 王丽娟)
| [1] |
录井技术现状及发展趋势 [J].Current status and trends of mud logging techniques [J]. |
| [2] |
数据挖掘技术在石油天然气勘探领域的应用探索 [J].Application of the data mining techniques in exploring the oil and natural gas [J]. |
| [3] |
|
| [4] |
利用录井图版判别渤海油田原油性质的新方法 [J].A new method to discriminate crude oil properties with mud logging charts in Bohai Oilfield [J]. |
| [5] |
|
| [6] |
渤海海域新近系稠油油藏原油特征及形成机制 [J].Crude features and origins of the Neogene heavy oil reservoirs in the Bohai Bay [J]. |
| [7] |
|

/
| 〈 |
|
〉 |
{kind=link}
{kind=link}